Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
7 Distributed/Federated Learning over 5G system
7.1 Uncompressed Federated Learning for image recognition
7.1.1 Description
7.1.2 Pre-conditions
7.1.3 Service Flows
7.1.4 Post-conditions
7.1.5 Existing features partly or fully covering the use case functionality
7.1.6 Potential New Requirements needed to support the use case
...
...
7 Distributed/Federated Learning over 5G system p. 44
7.1 Uncompressed Federated Learning for image recognition p. 44
7.1.1 Description p. 44
Nowadays, the smartphone camera has become the most popular tool to shoot image and video, which holds many valuable vision data for image recognition model training. For many image recognition tasks, the images/videos collected by mobile devices are essential for training a global model. Federated Learning (FL) is an increasingly widely-used approach for training computer vision and image recognition models.
In Federated Learning mode, the cloud server trains a global model by aggregating local models partially-trained by each end devices based on the iterative model averaging [30]. As depicted in Figure 7.1-2, within each training iteration, a device performs the training based on the model downloaded from the AI server using the local training data. Then the device reports the interim training results (e.g., gradients for the DNN) to the cloud server via 5G UL channels. The server aggregates the gradients from the devices, and updates the global model. Next, the updated global model is distributed to the devices via 5G DL channels, the devices can perform the training for the next iteration.
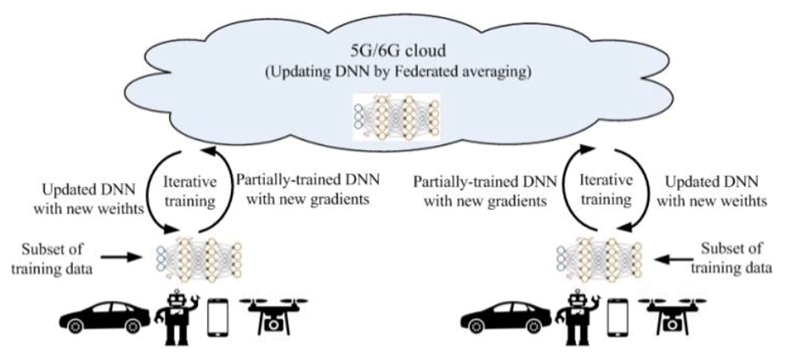
An iterative Federated Learning procedure is illustrated in Figure 7.1.1-2. In the Nth training iteration, the device performs the training based on the model downloaded from the FL training server using the images/videos collected locally. Then the device reports the Nth-iteration interim training results (e.g., gradients for the DNN) to the server via 5G UL channels. Meanwhile, the global model and training configuration for the (N+1)th iteration are sent to the device. When the server aggregates the gradients from the devices for the Nth iteration, the device performs the training for the (N+1)th iteration. The federated aggregation outputs are used to update the global model, which will be distributed to devices, together with the updated training configuration.
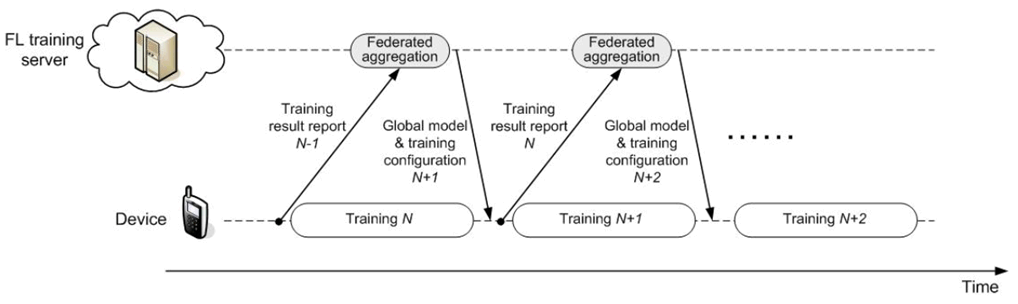
In order to fully utilizing the training resource at device and minimizing the training latency, the training pipeline shown in Figure 7.1.1-2 requires the training results report for the (N-1)th iteration and the global model/training configuration distribution for the (N+1)th iteration are finished during the device's training process for the Nth iteration. The analysis in clause 7.1.6 will be developed based on the processing timeline. In practice, more relaxing FL timeline can also be considered with sacrificing the training convergence speed.
The training time should be minimized since mobile devices may only stay in an environment for a short period of time. Further, considering the limited storage at device, it may not realistic to require the training device to store a large amount of training data in the memory for a training after it moves outside the environment.
Different from the decentralized training operated in cloud datacenters, Federated Learning over wireless communications systems need to be modified to adapt to the variable wireless channel conditions, unstable training resource on mobile devices and the device heterogeneity [10], [32], [34]. The Federated Learning protocol for wireless communications can be depicted in Figure 7.1.1-3 [10], [31]-[32].
For each iteration, the training devices can firstly be selected. The candidate training devices report their computation resource available for the training task to the FL server. The FL server makes the training device selection based on the reports from the devices and other conditions, e.g. the devices' wireless channel conditions, geographic location, etc..
Hereby, besides performing federated learning task, the training devices in a communication system have their other data to transmit at uplink (e.g. for ongoing service transactions), that may be high priority and not latency-tolerant and its transmission may affect a device's ability to upload the locally trained model. Device selection must therefore account for a trade-off to upload the training results as compared to uploading other uplink data. Furthermore, skipping a device from federated learning model aggregation for one or more iterations affects the convergence of the federated learning model. Therefore, candidate training device selection over wireless links is more complex as compared to federated learning in data centers.
After the training devices are selected, the FL server will send the training configurations to the selected training devices, together with global model for training. A training device starts training based on the received global model and training configuration. When finishing the local training, a device reports its interim training results (e.g., gradients for the DNN) to the FL server. In Figure 7.1.1-3, the training device selection is performed, and the training configurations are sent to the training devices at the beginning of each iteration. If the conditions (e.g. device's computation resource, wireless channel condition, other service transactions of the training devices) are not changed, the training device re-selection and training re-configuration might not be needed for each iteration, i.e. the same group of training devices can participate the training with the same configuration for multiple iterations. Still, the selection of training devices should be alternated over time in order to achieve an independent and identically distributed sampling from all devices, i.e., give a fair chance to all devices to contribute to the aggregated model.
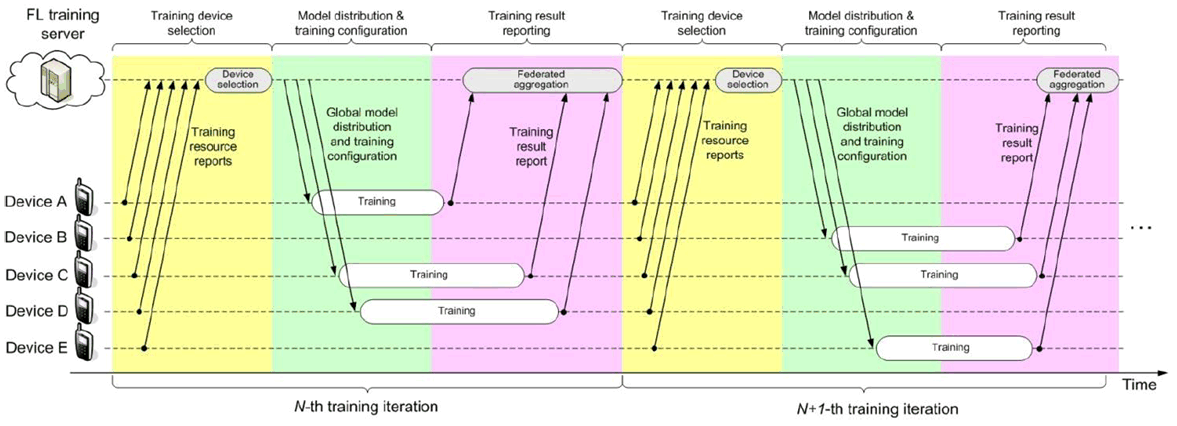
Figure 7.1.1-3: Typical Federated Learning protocol over wireless communication systems
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
7.1.2 Pre-conditions p. 46
The UE runs an application providing the capability of Federated Learning (FL) for the image recognition task.
The FL application on the UE is capable to report its interim training results to the FL server.
The FL server is capable to aggregate the interim training results from the federated UE, form the global model, and distribute the global model for training in the next iteration.
The 5G system has the ability to provide 5G network related information to the FL server.
7.1.3 Service Flows p. 46
- The FL server selects a set of federated UEs based on different own criteria. One possibility is to use available information on UE geographic location (subject to user consent and/or operator/regulatory requirements).
- The FL server distributes the global model to be federated UEs via 5G network.
- The FL application in a federated UE performs the training based on the local training data set collected by the UE, and then reports the interim training results (e.g., gradients for the DNN) to the FL server via 5G network.
- The FL server aggregates the gradients from the UEs, and updates the global model.
- Redo Step 1) to 4) for the training for the next iteration.
7.1.4 Post-conditions p. 47
The AI/ML model for image recognition is trained and converges, and the training accuracy and latency need to be guaranteed.
The FL training task for image recognition can be completed under the available computation and energy resource of the federated UEs. And the consumed the computation, communication and energy resources over the federated UEs and the FL server are optimized.
7.1.5 Existing features partly or fully covering the use case functionality p. 47
This use case mainly requires high data rate together with low latency. The high data rate requirements to 5G system are listed in Clause 7.1 and 7.6 of TS 22.261. As in Table 7.1-1 of TS 22.261, 300Mbps DL experienced data rate and 50Mbps UL experienced data rate are required in dense urban scenario, and 1Gbps DL experienced data rate and 500Mbps UL experienced data rate are required in indoor hotspot scenario. As in Table 7.6.1-1 of TS 22.261, cloud/edge/split rendering-related data transmission requires up to 0.1Gbps data rate with [5-10]ms latency countrywide.
7.1.6 Potential New Requirements needed to support the use case p. 47
As introduced in clause 7.1.1, in order to minimizing the training latency for Federated Learning for image recognition, the computation resource at device for the training task should be fully utilized, i.e. the training pipeline in Figure 7.1.1-1 is desired to be maintained.
If considering to train a 7-bit CNN model VGG16_BN using 224×224×3 images as training data, Table 7.1.6.1-1 shows the sum of gradient uploading latency, the federated aggregation latency and the global model downloading latency should be no larger than the GPU computation time at device for one iteration. For different batch sizes, the gradient uploading and the global model downloading for each iteration needs to be finished in [52~162ms], respectively.
Different from the "single-UE latency" considered by previous requirement study [15], what is more essential for synchronous Federated Learning is the latency within which all federated devices can finish the gradient uploading. In other words, all training devices need to finish the gradient uploading within the latency in Table 7.1.6.1-1, even if multiple training devices are present in a cell.
The size of the 8-bit VGG16_BN model is 132MByte for either the trained gradients or the global model. Hence in order to finish the gradient uploading and the global model downloading within the duration, the required UL and DL data rate are shown in Table 7.1.6.1-1, which are [6.5Gbit/s to 20.3Gbit/s] respectively. And it should be noted that 132MByte is the size without compression. The size may be reduced if advanced model/gradient compression techniques can be adopted.
In the legacy requirements to 5G system, e.g. [4], the full coverage is always desired for all UEs. However, the AI/ML model training task may to some extent relax the requirements on continuous network coverage. When a FL server selects the training devices for a Federated Learning task, it can try to pick the UEs in a satisfactory coverage, if they can collect the training data needed. This implies that even in a non-continuous coverage of 5G mmWave, the Federated Learning task can be well carried out. This provides to 5G operators a service better exploring the use of their FR2 spectrum resource.
7.1.6.1 Potential KPI Requirements p. 47
The potential KPI requirements needed to support the use case include:
[P.R.7.1-001]
The 5G system shall support a user experienced DL data rate as given in Table 7.1.6.1-1, to enable uncompressed Federated Learning for image recognition.
[P.R.7.1-002]
The 5G system shall support a user experience UL data rate as given in from Table 7.1.6.1-1, to enable uncompressed Federated Learning for image recognition.
| Mini-batch size (images) | GPU computation time (ms) | Maximum latency for trained gradient uploading and global model distribution (see note 1) | User experienced UL/DL data rate for trained gradient uploading and global model distribution (see note 2) |
|---|---|---|---|
| 64 | 325 | 3.24s | 325Mbit/s |
| 32 | 191 | 1.9s | 55Mbit/s |
| 16 | 131 | 1.3s | 810Mbit/s |
| 8 | 111 | 1.1s | 960Mbit/s |
| 4 | 105 | 1.04s | 1.0Gbit/s |
|
NOTE 1:
Latency in this Table is assumed 20 times the device GPU computation time for the given mini-batch size.
NOTE 2:
Values provided in the Table are calculative needs for an 8-bit VGG16 BN model with 132MByte size, given mini-batch sizes and a duration of [FFS] seconds per iteration. Necessary user experience UL/DL data rates can be reduced by e.g. setting longer times per iteration, applying compressed FL, or using another AI/ML model.
|
|||
![]()
![]()
![]()