Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
A.3 Training and inference p. 72
Training is a process in which a AI/ML model learns to perform its given tasks, more specifically, by optimizing the value of the weights in the DNN. A DNN is trained by inputting a training set, which are often correctly-labelled training samples. Taking image classification for instance, the training set includes correctly-classified images. When training a network, the weights are usually updated using a hill-climbing optimization process called gradient descent. The gradient indicates how the weights should change in order to reduce the loss (the gap between the correct outputs and the outputs computed by the DNN based on its current weights). The training process is repeated iteratively to continuously reduce the overall loss [25]. Until the loss is below a predefined threshold, the DNN with high precision is obtained.
There are multiple ways to train the network for different targets. The introduced above is supervised learning which uses the labelled training samples to find the correct outputs for a task. Unsupervised learning uses the unlabelled training samples to find the structure or clusters in the data. Reinforcement learning can be used to output what action the agent should take next to maximize expected rewards. Transfer learning is to adjust the previously-trained weights (e.g. weights in a global model) using a new training set, which is used for a faster or more accurate training for a personalized model [25].
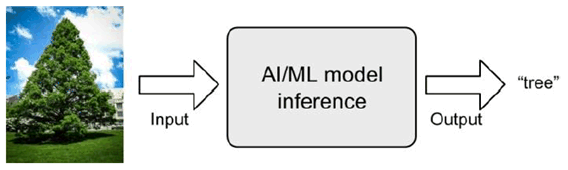
After a DNN is trained, it can perform its task by computing the output of the network using the weights determined during the training process, which is referred to as inference. In the model inference process, the inputs from the real world are passed through the DNN. Then the prediction for the task is output, as shown in Figure A.3-1. For instance, the inputs can be pixels of an image, sampled amplitudes of an audio wave or the numerical representation of the state of some system or game. Correspondingly, the outputs of the network can be a probability that an image contains a particular object, the probability that an audio sequence contains a particular word or a bounding box in an image around an object or the proposed action that should be taken [25].
The performance of DNNs is gained at the cost of high computational complexity. Hence more efficient compute engines are often used, e.g. graphics processing units (GPU) and network processing units (NPU). Compared to the inference which only involves the feedforward process, the training often requires more computation and storage resources because it involves also the backpropagation process [10].
![]()
![]()
![]()