Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
B General principle of split AI/ML operation between AI/ML endpoints p. 83
In recent years, the AI/ML-based mobile applications are increasingly computation-intensive, memory-consuming and power-consuming. Meanwhile end devices usually have stringent energy consumption, compute and memory cost limitations for running a complete offline AI/ML inference onboard. Hence many AI/ML applications currently intent to offload the inference processing from mobile devices to internet datacenters (IDC). Nowadays, even photos shot by a smartphone are often processed in a cloud AI/ML server before shown to the user who shot them. However, the cloud-based AI/ML inference tasks need to take the following factors into account:
- Computation pressure at IDCs As the estimates in [44], by 2021, nearly 850ZB data will be generated by end devices per year, whereas the global IDC traffic can only reach 20.6ZB. That means most of the data can only be left at network edge (i.e. devices and MEC) for AI/ML processing.
- Required data rate and latency Increasing number of AI/ML applications are requiring a high data rate meanwhile a low latency for communications between devices and the network, e.g. VR/AR, automatic driving, remote-controlled robotics. According to the estimates in [44] on device-initiated traffic, offloading all the data to cloud servers for AI/ML inference would consume excessive uplink bandwidth. This introduces challenging requirements on mobile communications system capacity, including for the 5G system.
- Privacy protection requirement The sensing/perception data supporting the inference in the cloud server often carry privacy of the end users. Different types of privacy protection problems need to be considered in case of either processing the data at the device or reporting it to the cloud/edge server. Compared to reporting it to the server, keeping the raw data at the device can reduce the pressure of privacy protection at the network side.
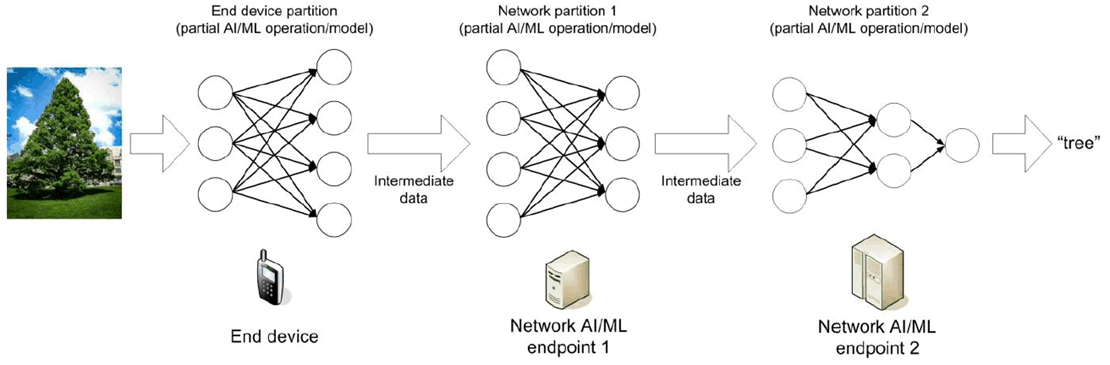
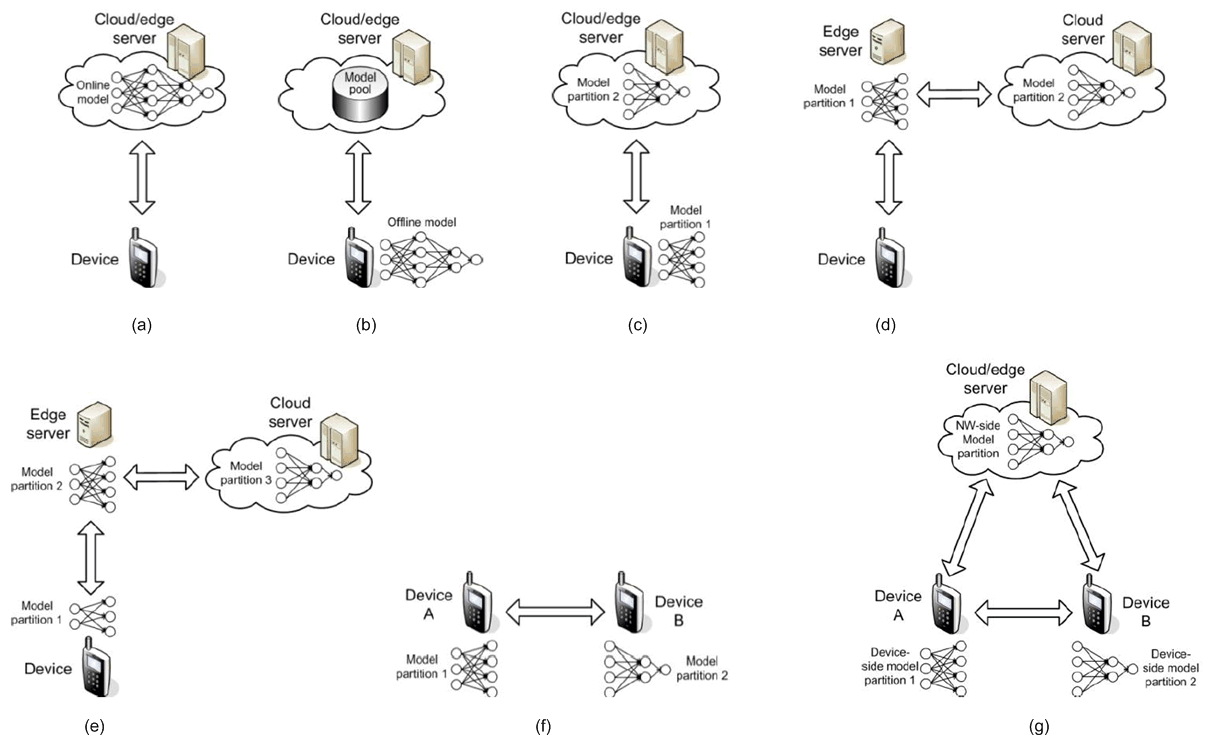
The modes for split AI/ML operations between device and network are illustrated in Figure B.1-2. The modes are in general applicable for AI/ML training as well as inference. In this section, we focus on the inference processing. Mode a) and b) are traditional schemes operating the AI/ML inference wholly on one endpoint. Mode c) - g) attempt to split the AI/ML inference or even the model into multiple parts according to the current task and environment, to alleviate the pressure of computation, memory/storage, power and required data rate on both device and NW endpoints, as well as to obtain a better model inference performance on latency, accuracy and privacy protection.
- Mode a): Cloud/edge-based inference In this mode (as shown in Figure B.1-2 (a)), the AI/ML model inference is only carried out in a cloud or edge server. The device only reports the sensing/perception data to the server, and does not need to support AI/ML inference operations. The server returns the inference results to the device. The advantage of this mode is limiting the device complexity. One disadvantage is that the inference performance depends on communications data rate and latency between the device and the server. Real-time uploading some perception data (e.g. high-resolution video streaming) requires a stably-high data rate and some AI/ML services (e.g. remote-controlled robotics) requires a stably-low latency, which are challenging to be guaranteed in 5G system due to different network coverages. And due to the disclosure of the privacy-sensitive data to the network, corresponding privacy protection measurements are required.
- Mode b): Device-based inference In this mode (as shown in Figure B.1-2 (b)), the AI/ML model inference is performed locally at the mobile device. The advantage is that, during the inference process, the device does not need to communicate with the cloud/edge server. Another motivation of this mode is preserving the privacy at the data source, i.e. the device, although the privacy protection problem needs also be considered at the device side. The disadvantage is potentially imposing an excessive computation/memory/storage resource to the device. And also pointed out by [10], we cannot assume the device always keep all the potentially-needed AI/ML models onboard. In some cases, the mobile device may need to obtain the AI/ML model from the edge cloud/server, which requires a corresponding downloading data rate from the 5G system, as introduced in Section 7.
- Mode c): Device-cloud/edge split inference In this mode (as shown in Figure B.1-2 (c)), an AI/ML inference operation or model is firstly split into two parts between the device and the cloud/edge server according to the current system environmental factors such as communications data rate, device resource, and server workload. Then, the device will execute the AI/ML inference up to a specific part or the DNN model up to a specific layer, and send the intermediate data to the cloud/edge server. The server will execute the remaining part/layers and sends the inference results to the device. Compared to Mode a) and b), this mode is more flexible and more robust to the varying computation resource and communications condition. A key link for this mode is to properly select the optimum split point between device side and network side based on the conditions.
- Mode d): Edge-cloud split inference This mode (as shown in Figure B.1-2 (d)) can be regarded as an extension of Mode a). The difference is that the DNN model is executed through edge-cloud synergy, rather than executed only on either cloud or edge server. The latency-sensitive part of an AI/ML inference operation or layers of an AI/ML model can be performed at the edge server. The computation-intensive parts/layers that the edge server cannot perform can be offloaded to cloud server. The device only reports the sensing/perception data to the server, and does not need to support AI/ML inference operations. The intermediate data are sent from the edge server to the cloud server. A proper split point needs to be selected for an efficient cooperation between edge server and cloud server.
- Mode e): Device-edge-cloud split inference This mode (as shown in Figure B.1-2 (e)) is the combination of Mode c) and d). An AI/ML inference operation or an AI/ML model is split over the mobile device, the edge server and the cloud server. The computation-intensive parts/layers of an AI/ML operation/model can be distributed among the cloud and/or edge server. The latency-sensitive parts/layers can be performed on the device or the edge server. The privacy-sensitive data can be left at the device. The device sends the intermediate data outcome from its computation to the edge server. And the edge server sends the intermediate data outcome from its computation to the cloud server. Two split points need to be selected for an efficient cooperation between the device, the edge server and the cloud server.
- Mode f): Device-device split inference This mode (as shown in Figure B.1-2 (f)) provides a de-centralized split inference. An AI/ML inference operation or model can be split over different mobile devices. A group of mobile devices can perform different parts of an AI/ML operation or different DNN layers for an inference task, and exchange intermediate data between each other. The computation load can be distributed over devices meanwhile each device preserves it private information locally.
- Mode g): Device-device-cloud/edge split inference Mode g) can be further combined with Mode c) or e). As shown in Figure B.1-2 (g), an AI/ML inference operation or model is firstly split into the device part and network part. Then the device part can be executed in a de-centralized manner, i.e. further split over different mobile devices. The intermediate data can be sent from one device to the cloud/edge server. Or multiple devices can send intermediate data to the cloud/edge server.
![]()
![]()
![]()