Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
5.2 Enhanced media recognition: Deep Learning Based Vision Applications
5.2.1 Description
5.2.2 Pre-conditions
5.2.3 Service Flows
5.2.4 Post-conditions
5.2.5 Existing features partly or fully covering the use case functionality
5.2.6 Potential New Requirements needed to support the use case
...
...
5.2 Enhanced media recognition: Deep Learning Based Vision Applications p. 16
5.2.1 Description p. 16
A tourist is wandering around a city and discovering the attractions and sights of the city. The user sees a beautiful object and she decides to shoot a video of the object. The application uses deep learning algorithms to process the video and identify the object of interest and provide historical information about it to the user. Furthermore, the application uses deep learning to reconstruct a 3D model of the object of interest by using the captured 2D video.
As an example, we investigate Feature Pyramid Network (FPN)-based object detection approaches. These networks are usually composed of a backbone FPN and a head that performs task-specific inference. The FPN processes the input images at different scales to allow for the detection of small-scale and large-scale features. The head may for instance segment the objects, infer a bounding box for the objects, or classify the objects.
The FPN backbone constitutes the most complex portion of the network and lends itself to be offloaded to the edge/cloud. The backbone is a common part to a wide range of networks that can perform different tasks. The produced feature maps can then be sent back to the UE for task-specific inference.
A breakdown of the network architecture is shown in the following Figure:
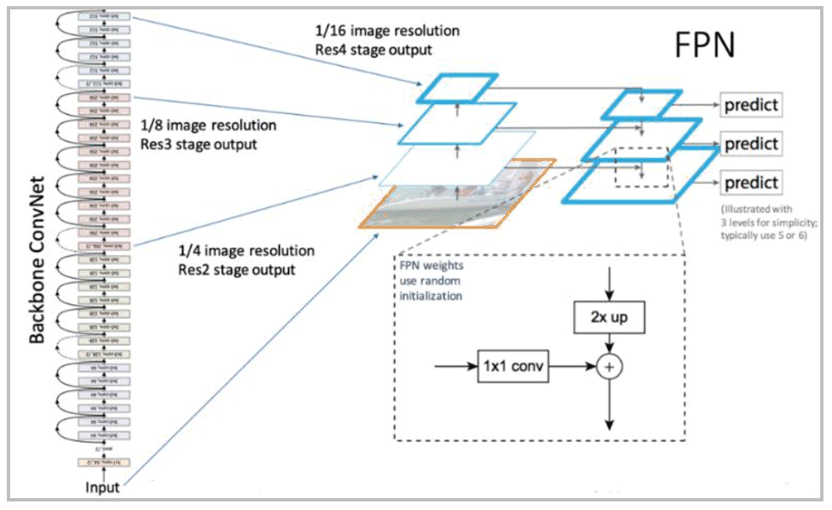
As shown in Figure 5.2.1-1, a classical CNN architecture is used as the core. The FPN is used to extract features at different scales of the image, making it scale-invariant. The prediction tasks constitute the head of the network. By plugging in different network heads, different AI tasks can be performed. This makes the network a Multi-Task Network (MTN). For example, a Region Proposal Network can be appended to detect and frame objects in the input sequence by outputting bounding boxes. Other Task-specific Heads can be appended to detect humans and poses, classify objects, track objects, etc.
5.2.2 Pre-conditions p. 17
The user wants to receive instantaneous information and reconstruction to enhance their experience. The user's device is battery operated.
5.2.3 Service Flows p. 17
- User opens their camera app and starts shooting a video
- Application pre-processes the video to prepare it for inference
- The application streams the extracted features and/or the video to the edge/cloud for processing.
- The network performs the split-inference (e.g. only running the backbone) and streams the results back to the client
- The application runs task-specific inference to solve the specific task of interest (e.g. object detection, tracking…)
- The application uses the inferred labels and classes to enhance the user's view
5.2.4 Post-conditions p. 17
The user gets enhanced information extracted from the video about the object of interest that the user was shooting a video of.
5.2.5 Existing features partly or fully covering the use case functionality p. 17
None.
5.2.6 Potential New Requirements needed to support the use case p. 18
The potential KPI requirements to support the use case are as given in Table 5.2.6.1-1, based on two examples of object detection models/algorithms:
- uplink streaming latency not higher than [100-200ms] and a user experienced UL data rate of [100-1500] kbit/s;
- downlink streaming latency not higher than [100-500ms] and a user experienced DL data rate of [32-150] Mbit/s;
| Recognition Task | Latency: maximum (see note 4) | User experienced DL data rate | User experienced UL data rate | ||
|---|---|---|---|---|---|
| Faster R-CNN [50] (see note 1) | YOLOv3 [51] (see note 2) | Faster R-CNN | YOLOv3 | ||
| Uplink Streaming | 100-200ms | 100-1000 kbit/s | 200-1500 kbit/s | ||
| Generic FPN Inference | 100-500ms | FPN:
4-10fps Sum(Pi)~1MB/frame 32-100Mbit/s uncompressed (see note 3) Compression factor 10~100 | Multiple scale (similar to FPN):
1.5 MB feature map/frame 40-150 Mbit/s uncompressed Compression factor 10~100 | ||
| Object Classification | 20-50ms | Performed on UE | Performed on UE | ||
| Bounding Box Detection | 20-50ms | Performed on UE | Performed on UE | ||
| Object Tracking | 50-150ms | Performed on UE | Performed on UE | ||
| Enhanced Information Retrieval | Few kBytes per request | Few kBytes per request | |||
| Overlay Rendering | 10ms | Performed on UE | Performed on UE | ||
|
NOTE 1:
Faster R-CNN uses an input image size of 3x224x224. The video is downscaled on the UE to that target resolution and then compressed (e.g. using HEVC) and streamed to the edge for further processing.
NOTE 2:
YOLOv3 uses an input image size of 3x416x416. The captured video is downscaled on the UE to the target resolution and compressed prior to streaming to the edge.
NOTE 3:
Faster R-CNN uses an FPN with ResNet 101 as backbone; thus resulting in feature maps {P2=(256x56x56), P3=(256x28x2), P4=(256x14x14), P5=(256x7x7)}.
NOTE 4:
the latency estimates assume an overall latency of around 1s from a user pointing at an object until overlay information is displayed to the user.
|
|||||
![]()
![]()
![]()