Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
5 Split AI/ML operation between AI/ML endpoints
5.1 Split AI/ML image recognition
5.1.1 Description
5.1.2 Pre-conditions
5.1.3 Service Flows
5.1.4 Post-conditions
5.1.5 Existing features partly or fully covering the use case functionality
5.1.6 Potential New Requirements needed to support the use case
...
...
5 Split AI/ML operation between AI/ML endpoints p. 12
5.1 Split AI/ML image recognition p. 12
5.1.1 Description p. 12
The AI/ML-based mobile applications are increasingly computation-intensive, memory-consuming and power-consuming. Meanwhile end devices usually have stringent energy consumption, compute and memory limitations for running a complete offline AI/ML inference on-board. Many AI/ML applications, e.g. image recognition, currently intent to offload the inference processing from mobile devices to internet datacenters (IDC). For example, photos shot by a smartphone are often processed in a cloud AI/ML server before shown to the user who shot them. However, the cloud-based AI/ML inference tasks need to take into account the computation pressure at IDCs, required data rate/latency and privacy protection requirement.
Image and video are the biggest data on today's Internet. Videos account for over 70% of daily Internet traffic [4]. Convolutional Neural Network (CNN) models have be widely used for image/video recognition tasks on mobile devices, e.g. image classification, image segmentation, object localization and detection, face authentication, action recognition, enhanced photography, VR/AR, video games. Meanwhile, CNN model inference requires an intensive computation and storage resource. For example, AlexNet [7], VGG-16 [8] and GoogleNet [9] require 724M, 15.5G and 1.43G MACs (multiply-add computation) respectively for a typical image classification task.
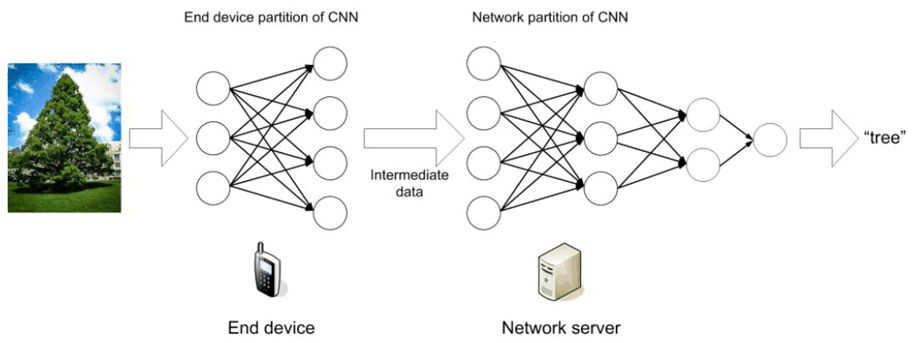
Many references [10]-[14] have shown that AI/ML inference for image processing with device-network synergy can alleviate the pressure of computation, memory footprint, storage, power and required data rate on devices, reduce end-to-end latency and energy consumption, and improve the end-to-end accuracy, efficiency and privacy when compared to the local execution approach on either side. The scheme of split AI/ML image recognition can be depicted in Figure 5.1.1-1. The CNN is split into two parts according to the current image recognition task and environment. The intention is to offload the computation-intensive, energy-intensive parts to network server, whereas leave the privacy-sensitive and delay- sensitive parts at the end device. The device executes the inference up to a specific CNN layer and sends the intermediate data to the network server. The network server runs through the remaining CNN layers. While the model is developed or invocated, the split AI/ML operation is based on the legacy model.
Due to the characteristics of some algorithms in the model training phase, a model has a certain degree of robustness[xx-xy]. Therefore, if there are errors in the intermediate data transmission, the model has a certain tolerance and can still guarantee the accuracy of the inference results. Since the inference result needs to be forwarded to the UE, the reliability of the inference result transmission needs to be guaranteed.
The split AI/ML image recognition algorithms can be analyzed based on the computation and data characteristics of the layers in the CNN. As shown in Figure 5.1.1-2 and Figure 5.1.1-3 (based on figures adopted from [13]), the intermediate data size transferred from one CNN layer to the next depends on the location of the split point. Hence, the required UL data rate is related to the model split point and the frame rate for the image recognition, as also observed by [13]-[14]. For example, assuming images from a video stream with 30 frames per second (FPS) need to be classified, the required UL data rate for different split points ranges from 4.8 to 65 Mbit/s (listed in Table 5.1.1-1). The result is based on the 227×227 input images. In case of images with a higher resolution, higher data rates would be required.
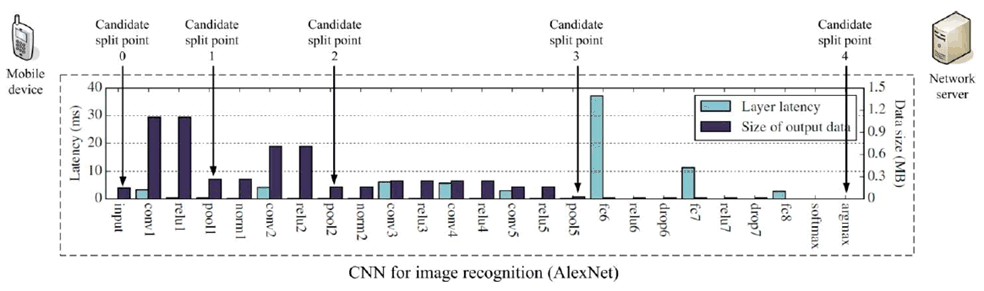
Figure 5.1.1-2: Layer-level computation/communication resource evaluation for an AlexNet model
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
| Split point | Approximate output data size (MByte) | Required UL data rate (Mbit/s) |
|---|---|---|
| Candidate split point 0
(Cloud-based inference) | 0.15 | 36 |
| Candidate split point 1
(after pool1 layer) | 0.27 | 65 |
| Candidate split point 2
(after pool2 layer) | 0.17 | 41 |
| Candidate split point 3
(after pool5 layer) | 0.02 | 4.8 |
| Candidate split point 4
(Device-based inference) | N/A | N/A |
VGG-16 is another widely-used CNN model for image recognition. Still assuming images from a video stream with 30 FPS need to be classified, the required UL data rate for different split points ranges from 24 to 720 Mbit/s (listed in Table 5.1.1-2).
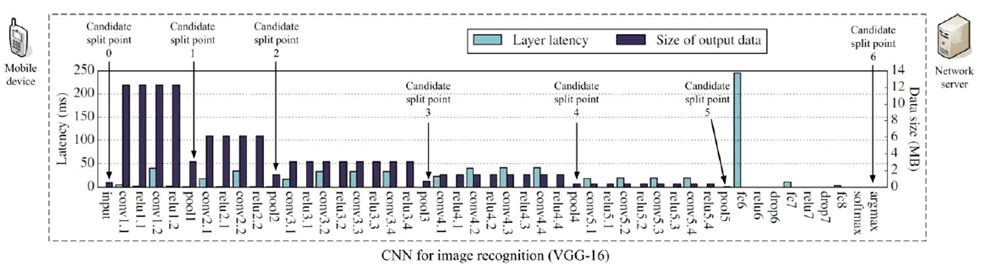
Figure 5.1.1-3: Layer-level computation/communication resource evaluation for a VGG-16 model
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
| Split point | Approximate output data size (MByte) | Required user experienced UL data rate (Mbit/s) |
|---|---|---|
| Candidate split point 0
(Cloud-based inference) | 0.6 | 145 |
| Candidate split point 1
(after pool1 layer) | 3 | 720 |
| Candidate split point 2
(after pool2 layer) | 1.5 | 360 |
| Candidate split point 3
(after pool3 layer) | 0.8 | 192 |
| Candidate split point 4
(after pool4 layer) | 0.5 | 120 |
| Candidate split point 5
(after pool5 layer) | 0.1 | 24 |
| Candidate split point 6
(Device-based inference) | N/A | N/A |
5.1.2 Pre-conditions p. 14
The involved AI/ML endpoints (e.g. UE, AI/ML cloud/edge server) run applications providing the capability of AI/ML model inference for image recognition, and support the split AI/ML image recognition operation.
The 5G system has the ability to provide 5G network related information to the AI/ML server.
5.1.3 Service Flows p. 14
- The AI/ML based image recognition application is requested by the user to start recognizing the image/video shot by the UE.
- Under the determined split mode and split point, the AI/ML based image recognition application in an involved AI/ML endpoint executes the allocated part of AI/ML model, and sends the intermediate data to the next endpoint in the AI/ML pipeline.
- After all the involved AI/ML endpoints finish the co-inference, the image recognition results are fed to the user using the results.
- The AI/ML based image recognition applications in the endpoints perform the split image recognition until the image recognition task is terminated.
5.1.4 Post-conditions p. 15
The objects in the input images or videos are recognized and the recognition accuracy and latency need to be guaranteed.
The image recognition task can be completed under the available computation and energy resource of the UE. And the consumed the computation, communication and energy resources over the AI/ML endpoints are optimized.
5.1.5 Existing features partly or fully covering the use case functionality p. 15
This use case mainly requires high data rate together with low latency. The high data rate requirements to 5G system are listed in Clause 7.1 and 7.6 of TS 22.261. As in Table 7.1-1 of TS 22.261, 300Mbps DL experienced data rate and 50Mbps UL experienced data rate are required in dense urban scenario, and 1Gbps DL experienced data rate and 500Mbps UL experienced data rate are required in indoor hotspot scenario. As in Table 7.6.1-1 of TS 22.261, cloud/edge/split rendering- related data transmission requires up to 0.1Gbps data rate with [5-10]ms latency countrywide.
5.1.6 Potential New Requirements needed to support the use case p. 15
The "image recognition latency" can be defined as the latency from the image is captured to the recognition results of the image are output to the user application, which was not specially addressed in [4] [15]. Following the principle of analyzing the latency and data rate requirements of split image recognition introduced in clause 5.1.1, the image recognition latency is related to the user application the recognition is used for.
Computer vision and image recognition have been widely used for many important mobile applications such as object recognition, photo enhancements, intelligent video surveillance, mobile AR, remote-controlled automotive, industrial control and robotics. The image recognition is usually a step of the processing pipeline of the application. And the recognition latency is a part of the end-to-end latency, as depicted in Figure 5.1.6-1.

Figure 5.1.6-1: Image recognition latency is a part of end-to-end latency
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
For example, if the image recognition results are just used for the object recognition e.g. unknown object recognition for smartphone user or criminal searching in database for intelligent security, it is acceptable that the image recognition is finished in seconds. If the image recognition result is used as an input to another time-sensitive application, e.g. AR display/gaming, remote-controlled automotive, industrial control and robotics, a much more stringent latency will be required. Based on the end-to-end latency requirements of the applications, the image recognition latency requirement can be derived, as listed in Table 5.1.6.1-1.
5.1.6.1 Potential KPI Requirements p. 15
The potential KPI requirements needed to support the use case include:
[P.R.5.1-001]
The 5G system shall support intermediate data uploading for split image recognition with a maximum latency as given in Table 5.1.6.1-1.
[P.R.5.1-002]
The 5G system shall support intermediate data uploading for split image recognition with a user experienced UL data rate as given in Table 5.1.6.1-1.
[P.R.5.1-003]
The 5G system shall support intermediate data uploading for split image recognition with communication service availability not lower than 99.999 %.
[P.R.5.1-004]
The 5G system shall support inference results downloading for split image recognition with reliability not lower than 99.999 % and intermediate data uploading for split image recognition with reliability not lower than 99.9%.
| User application | Latency: maximum | User experienced UL data rate | |||
|---|---|---|---|---|---|
| End-to-end latency | Image recognition latency | Intermediate data uploading latency | AlexNet
(Figure 5.1.1-1, see note 4) |
VGG-16
(Figure 5.1.1-2, see note 4) |
|
| One-shot object recognition at smartphone | Several seconds | ~1s | ~100ms | 1.6~21.6Mbit/s | 8~240Mbit/s |
| Person identification in security surveillance system | Several seconds | ~1s | ~100ms | 1.6~21.6Mbit/s | 8~240Mbit/s |
| Photo enhancements at smartphone | Several seconds | ~1s | ~100ms | 1.6~21.6Mbit/s | 8~240Mbit/s |
| Video recognition | Several seconds | 33ms@30FPS | ~10ms | 16~216Mbit/s | 80Mbit/s~2.4Gbit/s |
| AR display/gaming | 7~15ms (see note 1) | <5ms | 2ms | 80Mbit/s~1.08Gbit/s | 0.4~12Gbit/s |
| Remote driving | 10ms (see note 2) | <5ms | 2ms | 80Mbit/s~1.08Gbit/s | 0.4~12Gbit/s |
| Remote-controlled robotics | 10~100ms (see note 3) | <5ms | 2ms | 80Mbit/s~1.08Gbit/s | 0.4~12Gbit/s |
|
NOTE 1:
NOTE 2:
According to [46] the one-way latency required for remote driving is 5ms. The round-trip latency is assumed to be 10ms.
NOTE 3:
According to [5] the end-to-end latency required for video-operated remote-controlled robotics is 10~100ms.
NOTE 4:
As listed in Table 5.1.1-1 and Table 5.1.1-2, the intermediate data size for the split points of AlexNet and VGG-16 is 0.02 ~ 0.27MByte and 0.1 ~ 3MByte respectively.
|
|||||
![]()
![]()
![]()