Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
4 Overview
...
...
4 Overview p. 11
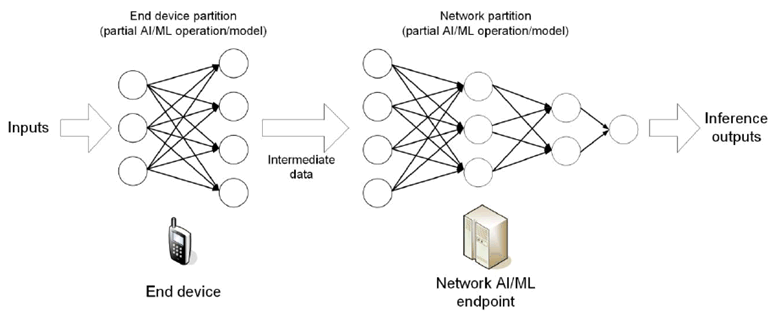
Artificial Intelligence (AI)/Machine Learning (ML) is being used in a range of application domains across industry sectors. In mobile communications systems, mobile devices (e.g. smartphones, automotive, robots) are increasingly replacing conventional algorithms (e.g. speech recognition, image recognition, video processing) with AI/ML models to enable applications. The 5G system can at least support three types of AI/ML operations:
- AI/ML operation splitting between AI/ML endpoints;
- AI/ML model/data distribution and sharing over 5G system;
- Distributed/Federated Learning over 5G system.
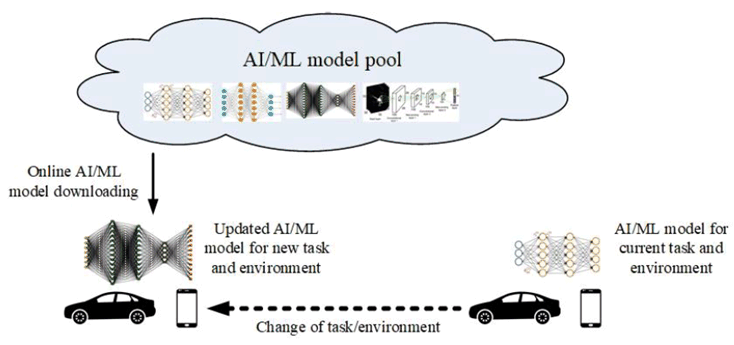
The scheme of AI/ML model distribution can be depicted as in Figure 4-2. Multi-functional mobile terminals might need to switch the AI/ML model in response to task and environment variations. The condition of adaptive model selection is that the models to be selected are available for the mobile device. However, given the fact that the AI/ML models are becoming increasingly diverse, and with the limited storage resource in a UE, it can be determined to not pre-load all candidate AI/ML models on-board. Online model distribution (i.e. new model downloading) is needed, in which an AI/ML model can be distributed from a NW endpoint to the devices when they need it to adapt to the changed AI/ML tasks and environments. For this purpose, the model performance at the UE needs to be monitored constantly.
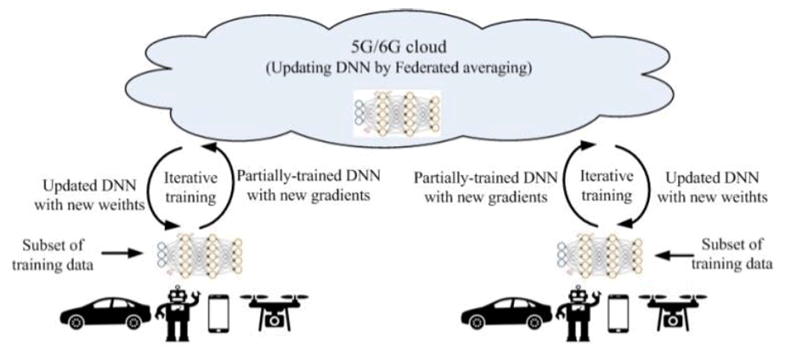
The scheme of Federated Learning (FL) can be depicted as in Figure 4-3. The cloud server trains a global model by aggregating local models partially-trained by each end devices. Within each training iteration, a UE performs the training based on the model downloaded from the AI server using the local training data. Then the UE reports the interim training results to the cloud server via 5G UL channels. The server aggregates the interim training results from the UEs and updates the global model. The updated global model is then distributed back to the UEs and the UEs can perform the training for the next iteration.
![]()
![]()
![]()