Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
7.3 Data Transfer Disturbance in Multi-agent multi-device ML Operations
7.3.1 Description
7.3.2 Pre-conditions
7.3.3 Service Flows
7.3.4 Post-conditions
7.3.5 Existing features partly or fully covering the use case functionality
7.3.6 Potential New Requirements needed to support the use case
...
...
7.3 Data Transfer Disturbance in Multi-agent multi-device ML Operations p. 52
7.3.1 Description p. 52
A brief story of machine learning is nothing but a computer (that has no or limited imprinted programs for a certain task) exploiting its own capability ("performance") towards a certain task using data ("experience"). There are several criteria to classify the types of Machine Learning depending on the characteristics of the method used. This use case is intended to describe a case of multi-agent multi-device ML operations with heavy data (i.e., the data size is huge) when there is partial or total disturbance for data collection/transfer (e.g., privacy regulation or temporary technical limitation like shortage of network resources or temporary failure). As depicted in Figure 7.3.1-1, this use case, Part I, is specifically related to a scenario that there are multiple agents and multiple collecting devices where the devices can perform ML operations, not necessarily in full but as much as they can (i.e., functional splitting is possible between a device and one or more learning agents).
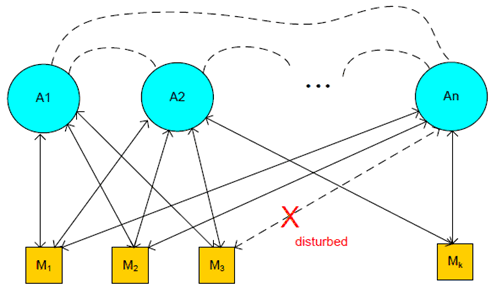
In the age that privacy was not affecting the flow of data from the source to the learning agent (e.g., a computer), the expected performance is the outcome of all possible computational considerations of the data collected (e.g., refer to the green solid curve of Figure 7.3.1-2). However, if there is a certain level of disturbance in data collection, the achievable performance toward the given task would not be as good as the one with no such disturbances (refer to the gap between the green solid curve and blue dotted curve in the same Figure). Some examples of such disturbances include:
- privacy regulations, such as EU's General Data Protection Regulation (GDPR) or California Consumer Privacy Act (CCPA);
-
limited capability of transport-layers, such as lack of network resources (e.g., radio resources due to temporal degradation, higher noise/interference level, highly crowed situations, partial/total break-down, and so on) preventing input data from being delivered in time:
- case 1: a portion of input data delivered in time, if any, is still useful (i.e., entropy can get increased/ improved)
- case 2: a portion of input data delivered in time, if any, is not useful (i.e., it's not enough to get entropy increased/ improved)
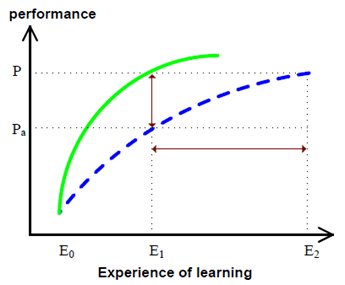
Figure 7.3.1-2: Performance gap vs. experience of learning for a given task: (1) with disturbance of input data collection/transfer (green, solid) (2) without disturbance of input data collection/transfer (blue, dotted).
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
Figure 7.3.1-3 shows an example of possible preparation action that can be taken in UE side if some predictive information can be made available when disturbance is about to happen. In the Figure, the preferred deadline for input data transfer is 1 sec (t = t0+1) with the amount of useful "input data" 3 bits in which two different kinds of scheduling are given: (a) is imperfect scheduling whereas (b) is good scheduling as an example, respectively. In reality, the transfer payload type is not limited to "input data" for learning agent(s) and it can also be applied to "learning model" transfer. The transfer direction can be "uplink" (e.g., for input data transfer) or "downlink" (e.g., for model distribution/transfer). This simplified example is intended to explain the justification why new technical requirements would be needed especially when some disturbance exists (e.g., by regulatory or technical causes).
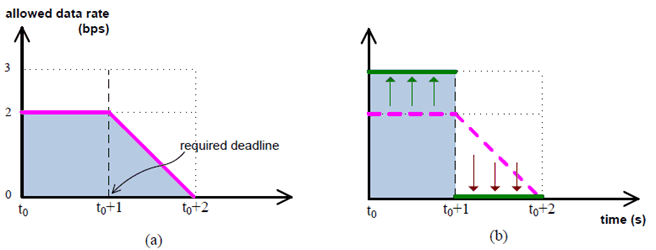
Given the regulatory disturbance, it is intended to minimize (or to prepare to minimize) the impact on transfer caused by technology (e.g., scheduling and/or information necessary for 3GPP entity to perform "good scheduling"). The expected requirements and service flow description are as follows.
7.3.2 Pre-conditions p. 54
There are three UEs M1, M2 and M3 (computers or learning machines in the form of a UE).
There are two learning agents/servers in the cloud.
UEs M1, M2 and M3 collect data and they process the data for learning they have collected or are collecting, if available, but they don't have to complete the processing due to limited computational capability.
Each UE (M1, M2 and M3, respectively) has a functional splitting point negotiated with their agent(s) regarding data processing for learning.
Agent A1 working with agent A2 for a task can share its outcome with agent A2 so that the outcome from agent A2 can jointly improve the outcome, if possible, which is possibly better than A1's individual outcome and A2's individual outcome.
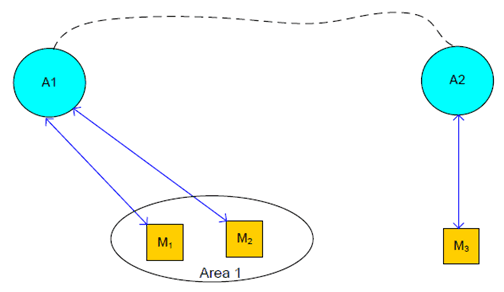
UE M1 and UE M2 are located in Area 1 of some jurisdiction that doesn't restrict collecting certain type of data.
Initial connections:
UE M1 is connected to agent A1 (via eNB, ng-eNB, or gNB) when data connection is necessary (e.g., when needed to upload some data or when needed to download some model).
- Agent A1 provides UE M1 with an alternative agent (i.e., Agent A2) for the use of disturbance, which is (one of) participating agent(s) that agent A1 shares data. [See Description clause for typical types of data]
- UE M1 is transferring learning data to agent 1.
- Agent A1 provides UE M2 with an alternative agent (i.e., Agent A2) for the use of disturbance, which is (one of) participating agent(s) that agent A1 shares data.
- UE M2 is transferring learning data to agent 1.
- Agent A2 provides UE M3 with an alternative agent (i.e., Agent A1) for the use of disturbance, which is (one of) participating agent(s) that agent A2 shares data.
- UE M3 is transferring learning data to agent 2.
7.3.3 Service Flows p. 55
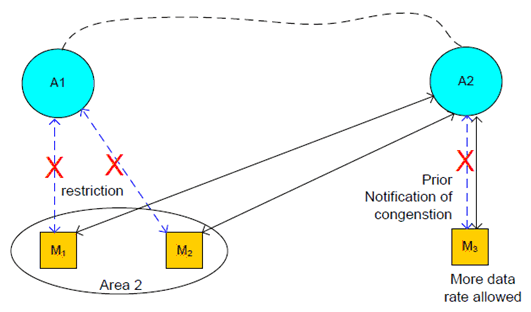
While transferring learning data to agent A1, UEs M1 and M2 move into Area 2 of some jurisdiction that has restrictive regulations for agent A1 to collect data from UEs within a specific area (or outside a specific area).
As a result, UEs M1 and M2 are restricted to transfer their data to agent 1.
While transferring learning data to agent A2, UE M3 moves into a different area where 5G system provides prior notification on possible traffic congestion which might disturb UE M3 from keeping transferring learning data to agent A2.
UE M3 makes a selection of an action policy: (action 1) to defer the transfer or (action 2) to request to speed up the transfer.
- If action 1 is selected, UE M3 will resume transferring when it becomes available (not the main focus of this use case);
- If action 2 is selected, UE M3 will be able to (2a) more urgent/useful segment of data (send priority one over the other) and/or (2b) request more network resources to use.
Modified connections (UEs M1 and M2):
UE M1 attempts to get connected to agent A2 based on the information that agent A1 has provided when initially connected.
- UE M1 keeps transferring the data to agent A2
- Agent A1 can share the collected data or its processed form of data, vice versa
- UE M1 keeps transferring the data to agent A2
- Agent A1 can share the collected data or its processed form of data, vice versa
7.3.4 Post-conditions p. 56
| Post-condition | Description in Communication aspects | Description in AI/ML operation aspects |
|---|---|---|
| #1 | UE M1 and UE M2 can continue to transfer data. | Agent A1 and Agent A2 could continue to improve the outcome (e.g., learning model) even when disturbance happens. |
| #2 | UE M3 can (1) send priority portion of data over the other and/or (2) complete the transfer or maximize the transfer completion ratio before congestion happens. | Agent A2 could minimize the impact of temporal traffic congestion as UE M3 (1) transferred priority portion of data and (2) transferred more data to Agent A2 before traffic congestion happens and disturbs. |
7.3.5 Existing features partly or fully covering the use case functionality p. 57
7.3.6 Potential New Requirements needed to support the use case p. 57
In Table 7.3.6-1, the service-level implications of AI/ML operation are summarized in the third column of Table 7.3.6-1, which are used to derive high-level potential service requirements in communication layer in order to support the AI/ML operation.
| PR | Potential Requirements in Communication aspects | Implications in AI/ML operation aspects (see note 1) |
|---|---|---|
| [PR.7.3-001]
(see note 2) | 5G system shall provide a suitable means for a learning agent of the AI/ML operations service to use when providing a 5GS using AI/ML application with information (e.g., required increase in data rate due to changes in AI/ML operation, etc. requested by AI/ML application (e.g., of the learning agent or of UE)) necessary to minimize or avoid the impact of communication disruption on AI/ML service/performance.
| From this Use Case, the relevant AI/ML aspect is "A learning agent is able to provide a UE with information on candidate participating learning agents." The above aspect can be supported by application layer above 3GPP transport layer. However, when transferring the learning data (processed, unprocessed or half-processed), if there are some changes in AI/ML layer to satisfy (e.g., triggered by some cause (e.g., due to technical or jurisdiction issue), it is intended that 3GPP help minimize or avoid the service disruption. |
| [PR.7.3-002] | 5G system shall provide a suitable means for a UE to provide the AI/ML application of a learning agent with information (e.g., experienced data rate, communication disturbance, geographical location to the extent of jurisdiction (e.g., State level, country level), etc.) necessary to minimize or avoid the impact of communication disruption on AI/ML service/performance.
| From this Use Case, the relevant AI/ML aspect is "A UE is able to inform a learning agent of learning task splitting point." In the formulation of communication aspect, it is necessary that a collecting agent (UE in this case) provide some information for AI/ML application at the counterpart (which is the learning agent in the cloud) so that the learning agent can perform necessary actions in order to avoid or minimize the AI/ML service disruption. For this to happen, it is necessary that certain information in 5GS (UE) side be shared the learning agent in the cloud. |
| [PR.7.3-003]
(see note 3) | 5G system shall provide a means to supply prediction info (e.g., on traffic congestion, the related geographical area/spot) so that a UE or learning agent can minimize the impact of learning data transfer disturbance. | |
| [PR.7.3-004] (see note 4) (see note 5) [PR.7.3-004a] |
5G system shall be able to support adaptive scheduling (e.g., for network resource utilization for the communication between the 5G system and AI/ML application of a learning agent) according to increase or decrease of AI/ML traffic demand due to switching to a different AI/ML mode.
| From this Use Case, the relevant AI/ML aspect is "The learning agent in the cloud needs to be aware of data rate change (e.g., traffic demand increase or decrease) that has been caused or will be caused by changes in workload sharing such as start using or stop using task splitting, or changing task splitting point that can increase or decrease the workload to UE as a collecting agent, in other words, decrease or increase the traffic demand)". And this needs to be shared with 5GS in order for 5GS to be able to schedule efficiently. |
| [PR.7.3-xxy] | From this Use Case, what is required in AI/ML aspect is "The learning agent in the cloud or the learning agent in a UE is able to be aware of the disturbance that has happened in the counterpart (i.e., entity/UE that was transferring learning-related data to the learning agent)." | |
|
NOTE 1:
From this Use Case, the AI/ML aspects/implications are summarized based on which the PR in the left-hand column is formulated
NOTE 2:
It is one of possible scenarios that the learning agent can be located within MNO's network (e.g., for learning-based signal processing optimization for RAN entity (e.g., gNB)), which operation is outside the scope of 3GPP but is used for optimization in RAN operations. It is intended that some information (e.g., QoS monitoring info) becomes available for 5G system so that 5G system can take necessary actions (e.g., "impact of communication disruption" for heavy data transfer can be minimized or avoided, which are service disruption in real-world applications, such as basic service robots). It is not intended to violate the QoS level (e.g., 5QI) when increasing or decreasing data rate.
NOTE 3:
Disturbance by both jurisdiction (e.g., regional laws that prohibit personal data from being transferred) or by technical difficulty (e.g., traffic congestion for transferring heavy data for AI/ML) are considered in prediction.
NOTE 4:
The intended scope of optimizing the network resources includes: to minimize the performance degradation, to minimize temporary imbalance among multiple AI/ML sessions that have changes in their data rate demand due to switching to a different mode (e.g., start using task splitting or stop using task splitting due to some communication disturbance or release from such disturbing factors, respectively) of AI/ML learning operation for a given model.
NOTE 5:
the learning agent described in this requirement is in the cloud.
|
||
Table 7.3.6-2 provides a summary of performance requirements for different usage scenarios. The required KPIs are dependent upon usage scenarios, especially on the task splitting points of given tasks even under the same usage scenarios. The calculation procedure can be referred to in [36]-[39].
For an example of image size 32 x 32 x 3 (32 wide, 32 high, 3 depth/colour channels), the weight is 3072; for images with more respectable size 200 x 200 x 3 = 120,000 weights; For a simple ConvNet for CIFAR-10 classification, the regular Neural Network architecture is INPUT→CONV→RELU→POOL→FC (Input layer, convolutional layer, pooling layer and fully-connected layer).
EXAMPLE 1:
32 x 32 x 3 image and six 5 x 5 filters produce a new image of size 28 x 28 x 6! = 564,480
EXAMPLE 2 (Language understanding):
BERT_{base} with L = 12 (layers), H = 768 (hidden size), A = 12 (heads). The number of parameters = 110M
EXAMPLE 3 (Language understanding):
BERT_{large} with L = 24 (layers), H = 1024 (hidden size), A = 16 (heads). The number of parameters = 340M
EXAMPLE 4:
[39] for 8-bit VGG16 Pruned, it can reduce the original size (VGG-16 Ref) of 138MB by a factor of (1/13), which size will be approximately 10.3MB. Thus, 10.3MB / (GPU time / 2) ≒ 196MB/sec = 1.56Gb/sec.
| Description in Communication aspects | Description in AI/ML operation aspects (all inclusive) | Range (see note 2) | |||||
|---|---|---|---|---|---|---|---|
| End-to-end latency (see note 1) | User experienced data rate (see note 1) | Service interruption time | End-to-end latency | Data rate | Service interruption time | ||
| Learning data (raw data) at Service robot at initial launch (see note 4) | < 100 ms | UL: < [1.5] Gbit/s DL: < [500] Mbit/s | < 10 s | < [100] ms | < [500] km | ||
| Learning data (trained data) at Service robot at initial launch (see note 4) | < 50 ms | UL: < [50] Mbit/s DL: < [500] Mbit/s | < 10 s | < [100] ms | < [500] km | ||
| Learning data (raw data) at Service robot in routine operation (see note 4) | < 100 ms | UL: 700 Mbit/s DL: < [500] Mbit/s | < 1 s | < [100] ms | < [200] km | ||
| Learning data (trained data) at Service robot in routine operation (see note 4) | < 50 ms | UL: 50 Mbit/s DL: < [500] Mbit/s | < 1 s | < [100] ms | < [200] km | ||
| Remote control of robots (type 1) (see note 3) | < [5] ms | UL: < [700] Mbit/s DL: [1] Mbit/s | < [10] ms | < [10] ms | < [3] km (aerial, outdoor); < [500] m (indoor) | ||
| Remote control of robots (type 2) (see note 3) | < [20] ms | UL: < [700] Mbit/s DL: [1] Mbit/s | < [25] ms | < [100] ms | < [3] km | ||
|
NOTE 1:
The end-to-end latency and user experienced data rate are dependent on which learning model the UE and agent have selected to use. The expected user experienced data rate varies depending on the task splitting point between UE and the learning agent. The suggested number in this Table is based on the maximum possible value (e.g., non-splitting cases or on splitting stage at pooling).
NOTE 2:
The range is a rough measure, which may include radio and core network segments, between a Service Robot (as a UE) and the learning agent (including candidate learning agent). For routing operation, the range is typically smaller than that for initial launch of a task/job site.
NOTE 3:
For robot control, only two categories are suggested. A refined use of more categories is FFS. Type 1 requires more rigorous KPIs (e.g., helicopter, humanoid robots). This case is not intended to cover more rigorous and/or complicated operational environments such as a use case with a very long communication range and tactile/haptic feedback related use cases demanding ultra-fast delivery of skillsets, e.g., in (or less than) the order of milliseconds.
NOTE 4:
In these scenarios, service robots are assumed to have basic robotics mobility. DL (downlink) data rate requirement is characterised by the required upper bound that can often happen sporadically, e.g., when downloading AI/ML models.
|
|||||||
![]()
![]()
![]()