Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
7.2 Compressed Federated Learning for image/video processing
7.2.1 Description
7.2.2 Pre-conditions
7.2.3 Service Flows
7.2.4 Post-conditions
7.2.5 Existing features partly or fully covering the use case functionality
7.2.6 Potential New Requirements needed to support the use case
...
...
7.2 Compressed Federated Learning for image/video processing p. 48
7.2.1 Description p. 48
Federated learning can be used to train AI/ML models based on number of images and videos generated by cameras in mobiles devices by iteratively exchanging gradient of updating models instead of direct user images and videos. Because this method can utilize images and videos from many users, the performance of a trained AI/ML model can be significantly higher than a stand-alone case. However, the basic federated learning methods can have disadvantages by massive uplink traffics and high computational cost at a mobile device. Therefore, it is beneficial to consider a compressed federated learning (CFL) method, which allows compressed (not full) models to be transferred during a learning period.
Figure 7.2.1-1 shows the essential procedure of CFL. CFL iteratively performs a set of the three operation stages. In order to describe the iterations in CFL, we introduce a cycle of I: each cycle begins with the 1st iteration and ends with I-th iteration, which is immediately followed by the 1st iteration of the next cycle (e.g., (I+1)st iteration). For each iteration, the three operation stages include the training UE selection, the sparse weight distribution, and the training result reporting stages. The operations of these three stages in the first iteration and the operation in the last iteration are different from the operations in the other iterations.
Each iteration in CFL starts with the training UE selection stage, at which the CFL server selects a set of available users from the candidate users to associate with the same purpose AI/ML model. To the selected users, ready to participate in the learning process because of being an available state, the CFL server transmits the train configuration information. At the next stage, the CFL server sends the sparse global model, which could be an initial version of the AI/ML model in the first iteration. Otherwise, the sparse global model is an aggregated version based on user reporting information.
Then, each UE trains a received model after expanding the spatial model and reports an intermediate training result to the CFL server, where the training result is comprised only of significant value weight gradients for applying a model compression. By doing so, uplink throughout requirement can be significantly reduced in comparison with the basic federated learning method without compression. In the last iteration, I-th iteration, the CFL Server sends 'train stop message' to UEs so that the UEs can stop sending its update any longer, and the CFL Server performs fine-tuning by pruning unnecessary nodes. Throughout these multiple iterations of a cycle (i.e., from the 1st iteration through the I-th iteration) as in the Figure, the AI/ML model will be progressively enhanced based on user data in mobile networks at reduced requirements of uplink and downlink throughput.
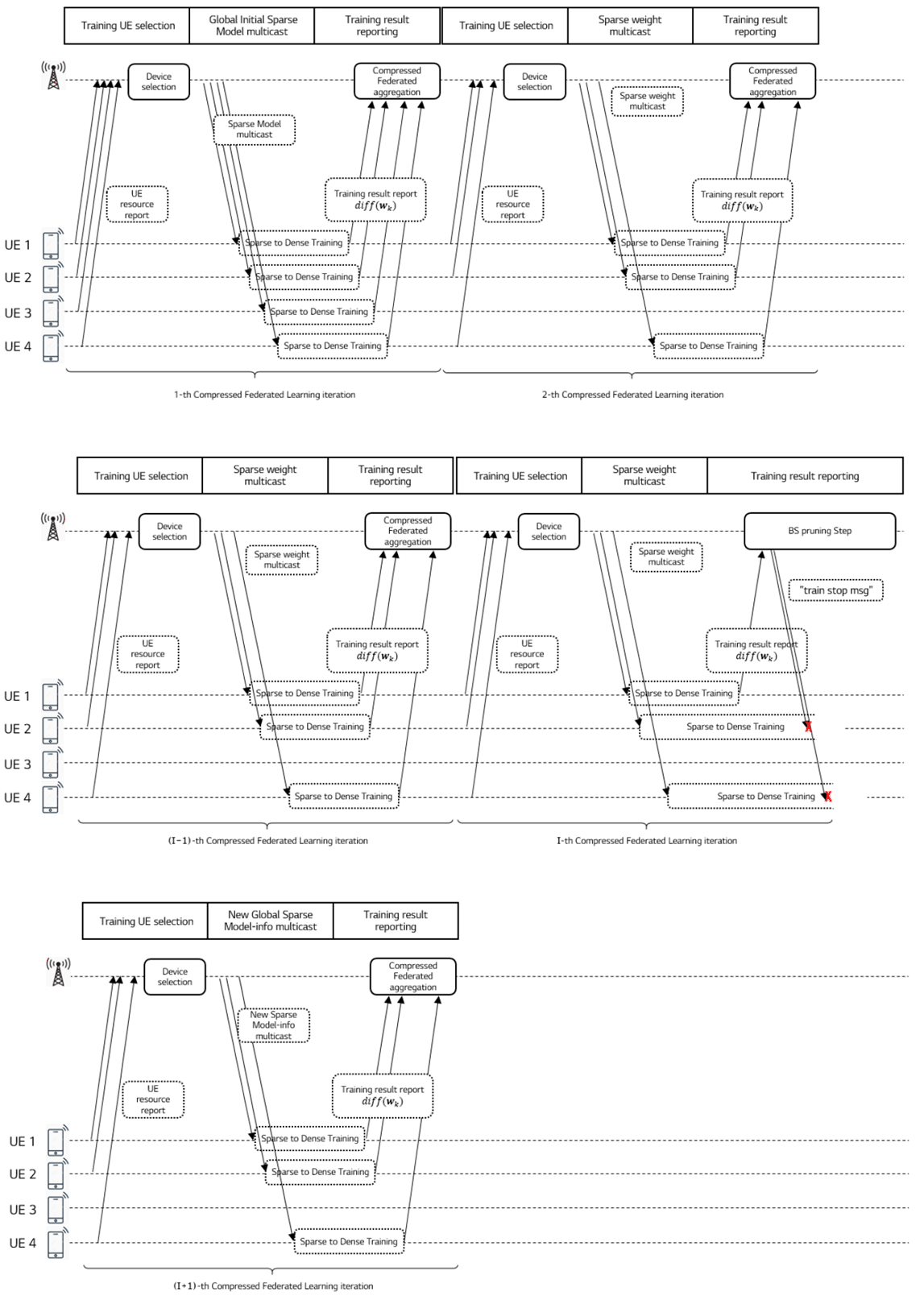
Figure 7.2.1-1: Compressed Federated Learning timeline for image recognition
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
7.2.2 Pre-conditions p. 50
UE can have a computational hardware and algorithm capability to train an AI/ML model such as for an image and video cognition.
UE can send intermediate training results to a CFL server.
A CFL server can select training devices and determine training configuration.
A CFL server can aggregate intermediate training results and generate a sparse global model for the next learning iteration.
A CFL server can distribute a global AI/ML mode to a set of selected users.
7.2.3 Service Flows p. 50
Step 1:
The CFL server selects the training users from candidate users.
Step 2:
The CFL server sends the configuration information to the selected users.
Step 3:
The CFL server distributes the initial (or, aggregated) sparse global model to the selected users through a 5G networks.
Step 4:
Each UE expands the sparse global model and train the expanded model using its local data. Then, each UE sends only significant value weight gradients to the CFL server.
Step 5:
The CFL server aggregates the training results received from the training UEs and update a global model using the aggregated results.
Step 6:
Until the AI/ML model reaches saturated performance enhancement, the process runs repeatedly from step 1.
Step 7:
Otherwise, the CFL server performs fine-tuning for a global model compression for a global model. This process can be applied regularly so as to improve bandwidth and computation resource efficiency before the training finalization.
Finally, the CFL server distributes the new sparse global model to all users which needs the same AI/ML model.
7.2.4 Post-conditions p. 50
For a UE prospective, CFL can reduce uplink and downlink throughput requirements for the federated learning process. Also, the computational complexity in UEs can be significantly reduced because of enabling a compressed model.
7.2.5 Existing features partly or fully covering the use case functionality p. 50
Latency analysis for gradient uploading and the global model downloading for image recognition
AI/ML model training data for CFL is a new type of traffic. Consider CFL to train an 8-bit CNN VGG16 model with 224x224x3 images. Table 7.2.5-1 shows that the single GPU computation time should be larger than the addition of gradient uploading latency and global model downloading latency.
Table 7.2.5-1: GPU computation time for different mini-batch sizes for Compressed Federated Learning
| Mini-batch size
(images) |
GPU computation time (ms) | Required latency for trained gradient uploading (sec) (see note 1) | Required latency for global model distribution (sec) (see note 1) |
|---|---|---|---|
| 64 | 325 | 3.25 | 3.25 |
| 32 | 191 | 1.91 | 1.91 |
| 16 | 131 | 1.31 | 1.31 |
| 8 | 111 | 1.11 | 1.11 |
| 4 | 105 | 1.05 | 1.05 |
|
NOTE 1:
Latency in this Table is assumed 20 times the device GPU computation time for the given mini-batch size.
|
|||
Data rate analysis for gradient uploading and the global model downloading for image recognition
Table 7.2.5-2 shows the required data rate for gradient uploading and global model downloading for the above 8-bit VGG16 model when CFL is applied. We calculated the required data rate based on Table 1 in [39], in which the pruning size of the 8-bit VGG16 model can be reduced 13 times from the original size of 138 Mbyte. It is noteworthy that 13 times model compression gives almost no accuracy degradation for the 8-bit VGG16 model. If we assume that the minibatch size is 4, the uplink required rate is compressed trained parameter size * 8 / (GPU computation time / 2) = (138 / 13) Mbyte * 8 bits / ((105ms*20/1000) / 2) = 80.88 Mbit/s which is same to the downlink require rate.
| Mini-batch size
(images) |
User experienced UL data rate for trained gradient uploading (Mbit/s)
(see note 2) |
User experienced DL data rate for global model distribution (Mbit/s)
(see note 2) |
|---|---|---|
| 64 | 26.13 | 26.13 |
| 32 | 44.46 | 44.46 |
| 16 | 64.83 | 64.83 |
| 8 | 76.51 | 76.51 |
| 4 | 80.88 | 80.88 |
| User experienced data rate = compressed trained parameter size * 8 / (GPU computation time / 2) | ||
|
NOTE 2:
Values provided in the Table are calculative needs for an 8-bit VGG16 BN compressed model with 10.61MByte size, given mini-batch sizes per iteration.
|
||
In the case of 8-bit CNN VGG16, CFL compared to FL can transmit up to 13 times more model information through model compression. Hence, when using the same uplink payload as FL, up to 13 times more users can be simultaneously supported. For example, as shown in Figure 7.2.5-1 which is redrawing using the associated data in [50], the accuracy performance of the FL with 15 participants, which is five times than the FL with 3 participants, can be significantly increased by 6.5%. If we consider the maximum compression efficiency of CFL with supporting 13 times more users, a further performance gain is expected.
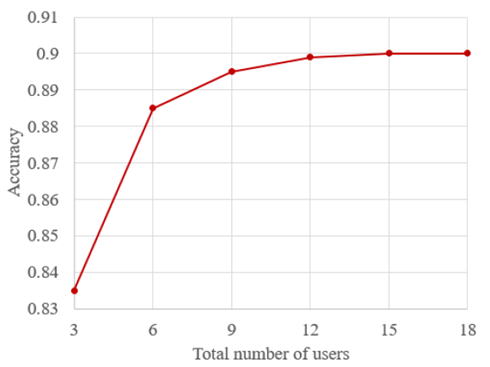
Figure 7.2.5-1: Federated Learning accuracy as the total number of users
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
Redrawing using the associated data in [60]
For the flexibility and accuracy of FL, the compression rate of CFL can be adjusted according to the user's channel conditions. For example, even in the case of a user with a bad channel, the problem of not participating in FL can be solved by increasing the compression ratio of the model.
7.2.6 Potential New Requirements needed to support the use case p. 52
[P.R.7.2.6-001]
The 5G system shall support to upload a trained gradient for each iteration of Compressed Federated Learning with a maximum latency of 1.05~3.25s.
[P.R.7.2.6-002]
The 5G system shall support downloading the global model for each iteration of Compressed Federated Learning with a maximum latency of 1.05~3.25s.
[P.R.7.2.6-003]
The 5G system shall support UL unicast transmission with 26.13~80.88Mbit/s user experienced UL data rates and a communication service availability not lower than [99.9%] for reporting the trained gradients for Compressed Federated Learning.
[P.R.7.2.6-004]
The 5G system shall support DL multicast transmission with 26.13~80.88Mbit/s user experienced DL data rates and a communication service availability not lower than [99.9%] for distributing the global model for Compressed Federated Learning.
![]()
![]()
![]()