Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
C General principle of AI/ML model/data distribution and sharing over 5G system p. 95
For the inference tasks which requires low latency and desires the privacy-sensitive data to be preserved at the UE side, offline AI/ML inference is desired, rather than the cloud-based inference. However, an offline AI/ML model running on mobile devices must have a relatively low computation complexity and a small storage size. An approach to enabling offline DNN models on mobile devices is to compress the model to reduce its resource and computational requirements [27]-[28], [35], [45]. However, DNN compression will lead to loss of inference accuracy and adaptivity to various tasks and environments. A solution to this challenge is to adaptively select the model for inference from a set of trained models [10]. The model selection is motivated by the observation that the optimum model for inference depends on the input data and the precision requirement [20][45]. Multi-functional mobile terminals usually need to switch the AI/ML model in response to task and environment variations.
The condition of adaptive model selection is that the models to be selected have been available for the mobile device. However, given the fact that the DNN models are becoming increasingly diverse, and with the limited storage resource in a UE, it is unfeasible to pre-load all candidate AI/ML models on-board. Online model distribution (i.e. new model downloading) or online transfer learning (i.e. partial model updating) is needed. As illustrated in Figure C.1-1, an AI/ML model can be distributed from a NW endpoint to the devices when they need it to adapt to the changed AI/ML tasks and environments.
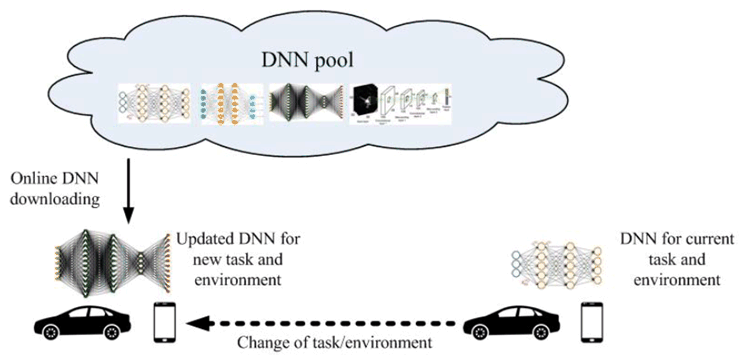
The model to be distributed can be determined in two ways: Requested by a device, or controlled by a network server. The condition of the first mechanism is that the device can make the model selection/re-selection decision based on the understanding to the oncoming AI/ML task, environment and the list of the models available at the network server. As shown in Figure C.1-2, a model selector on the device is trained to select the best DNN for different input data.
The model selector is trained to determine the optimum DNN model for a new, unseen input using a set of automatically tuned features of the DNN model input, and taking into consideration the precision constraint and the characteristics of the input.

The data rate for downloading the needed models depends on the following factors:
- Size of the model This depends on different AI/ML applications. Along with the increasing performance requirements to AI/ML operations, the sizes of the models also keep increasing, although model compression techniques are under improvements.
- Required downloading latency This depends on how fast the model needs to be ready at the device. It is impacted by the extent to which the oncoming application can be predicted. Considering the unpredictability of user behaviour and typical waiting time a user can tolerate, the downloading of the AI/ML model needs to be finished in seconds or even in milliseconds. Different from a streamed video which can be played when a small portion is buffered, a DNN model can only be used until the whole model is completely downloaded.
![]()
![]()
![]()