Content for TR 22.874 Word version: 18.2.0
0…
4
5…
5.2…
5.3…
5.4…
5.5…
6…
6.2…
6.3…
6.4…
6.5…
6.6…
6.7…
7…
7.2…
7.3…
7.4…
8…
A…
A.2
A.3
A.4
B
C
D…
D General principle of Distributed/Federated Learning over 5G system p. 100
With continuously improving capability of cameras and sensors on mobile devices, valuable training data, which are essential for AI/ML model training, are increasingly generated on the devices. For many AI/ML tasks, the fragmented data collected by mobile devices are essential for training a global model. In the traditional approaches, the training data gathered by mobile devices are centralized to the cloud datacenter for a centralized training.
However, an AI/ML model training often requires a large data set and significant computational resources for multiple weight-update iterations. Nowadays, most of the AI/ML model training tasks are performed in the power cloud datacenters since the resource consumption of the training phase significantly overweights the inference phase. In many cases, training a DNN model still takes several hours to multiple days. However, cloud-based training means that the enormous amount of training data should be shipped from devices to the cloud, incurring prohibitive communication overhead as well as the data privacy pressure at the network side [10]. Similar to the split AI/ML inference introduced in Annex B, AI/ML model training tasks can also work in a cloud-device coordination manner. Distributed Learning and Federated Learning are examples in this manner.
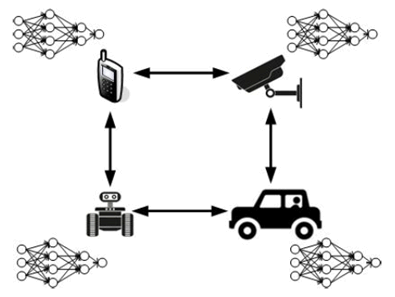
In Distributed Learning mode, as shown in Figure D.1-1, each computing node trains its own DNN model locally with local data, which preserves private information locally. To obtain the global DNN model by sharing local training improvement, nodes in the network will communicate with each other to exchange the local model updates. In this mode, the global DNN model can be trained without the intervention of the cloud datacenter [10].
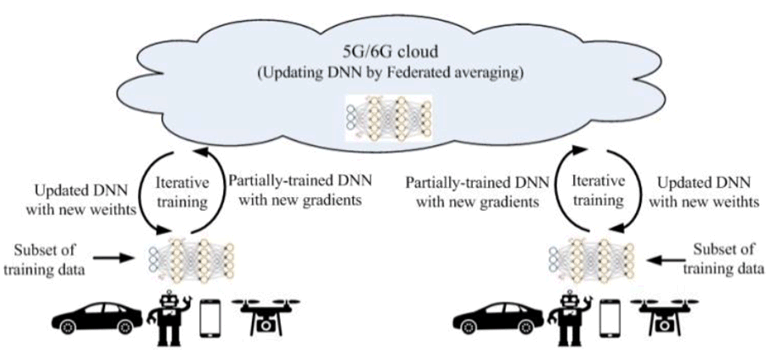
In Federated Learning (FL) mode, the cloud server trains a global model by aggregating local models partially-trained by each end devices. The most agreeable Federated Learning algorithm so far is based on the iterative model averaging [30]. As depicted in Figure D.1-2, within each training iteration, a UE performs the training based on the model downloaded from the AI server using the local training data. Then the UE reports the interim training results (e.g., gradients for the DNN) to the cloud server via 5G UL channels. The server aggregates the gradients from the UEs, and updates the global model. Next, the updated global model is distributed to the UEs via 5G DL channels. Then the UEs can perform the training for the next iteration.
The performance requirements for Distributed/Federated Learning are listed below. The requirements to 5G communication links (e.g. data rate, latency, reliability) can be derived from the following requirements.
- Training loss: Training loss is the gap between the correct outputs and the outputs computed by the DNN model which indicates how well the trained DNN model fits the training data. Aim of training task is to minimize the training loss. Training loss is mainly affected by the quality of the training data and the efficiency of the training methods, i.e. whether the meaning of training data can be fully and properly explored. For Federated Learning, only when the valuable local training data can be fully learned in the duration of the iteration and the local training updates can be correctly reported to the cloud server within the target duration, the training loss can be minimized. This implies that the requirements to the devices joining in the training process on the achievable UL data rate, latency and reliability for reporting the trained updates, and the achievable UL data rate, latency and reliability for distributing the model for training in next iteration. And to minimize the training loss with device heterogeneity (in computation and communication performance), training device selection and training configuration are needed before the training is performed in an iteration [31], [48] (will be introduced later in this section). The QoS of the relevant controlling messages, e.g. for training request, training resource reporting, training device selection, training configuration, and resource allocation for the training updates reporting, also needs to be guaranteed.
- Training latency: Training latency is one of the most fundamental performance metrics of AI/ML model training task since it directly influences when the trained model is available for use. Nowadays, cloud-based training often takes several hours to multiple days. The latency of the Distributed/Federated Learning process would take even a longer time if the computation latency or the communication latency is not minimized. The latency of the Distributed/Federated Learning process is determined by the convergence rate (e.g. number of iterations before the training process converges to a consensus) and the latency of each iteration which consists of computation latency and communication latency. The computation latency depends on the computation/memory resource available on training devices. The computation latency depends on the DL data rate available for model distribution and UL data rate available for trained model updating. The latency of the whole training process is determined by the larger one between the computation latency and the communication latency. Hence the latencies of the computation and communication links need to be cooperatively minimized. If the communication latency cannot match to the computation latency, the communication link will become the bottleneck and prolong the whole training process. For synchronous Federated Learning, in each iteration, the training latency is determined by the last device that reports its training update because the federated aggregation can be finished when all needed training updates are correctly gathered. That means the device heterogeneity (in computation and communication performance) will also highly impact the overall training latency. Rather than requiring the UL transmission latency of a specific device, the overall latency required for all training devices to upload the training updates (device-group latency) needs to be defined. And the QoS of the controlling messages for minimizing the device-group latency, e.g. for training request, training resource reporting, training device selection, training configuration, and resource allocation for the training updates reporting, also needs to be guaranteed.
- Energy efficiency: For Distributed/Federated Learning, both the computation and communication processes consume considerable energy. The Federated Learning architecture and protocol should also consider the power constraints on the training devices and the energy efficiency on device as well as the network side.
- Privacy: When training the DNN model by using the data originated at a massive of end devices, the raw data or intermediate data should be transferred out of the end devices. Compared to reporting it to the cloud/edge server, preserving privacy at the end devices can reduce the pressure of privacy protection at network side. For example, Federated Learning is an agreeable approach to avoid uploading the raw data from device to network, as a cloud-based training requires.
$ Change history p. 109
![]()
![]()