Content for TR 26.998 Word version: 18.0.0
0…
4…
4.2…
4.2.2…
4.2.2.2
4.2.2.3
4.2.2.4
4.2.3…
4.3…
4.4…
4.5…
4.6…
4.6.4…
4.6.5…
4.6.8…
5
6…
6.2…
6.2.4…
6.2.4.2
6.2.5…
6.3…
6.3.4…
6.3.4.2
6.3.5…
6.4…
6.4.4
6.4.5…
6.5…
6.5.4
6.5.5
6.5.6…
6.6…
6.6.4
6.6.5…
7…
8…
8.9
9
A…
A.2
A.3…
A.4
A.5
A.6
A.7…
8.9 Audio Media Pipelines for AR Experiences p. 99
8.9.1 Generic functional device architecture with audio subsystem (STAR-based UE) |R18| p. 99
In AR experiences the audio media consists of spatial audio in the form of audio sources as well as acoustic characteristics of the scene. Example device functional architectures, including audio subsystems, are shown in Figure 8.9-1, Figure 8.9-2 and Figure 8.9-3. In receiving, the audio subsystem may be implemented as a monolithic block (Figure 8.9-1); alternatively, the audio decoding and rendering may be closely integrated, e.g. in the XR Scene Manager Audio Subsystem (Figure 8.9-2) or split into an encoding-decoding process by the Media Access Functions with separated rendering by the XR Scene Manager Audio Subsystem (Figure 8.9-3). The separation of audio decoding and audio rendering may depend on the implementation and/or use cases.
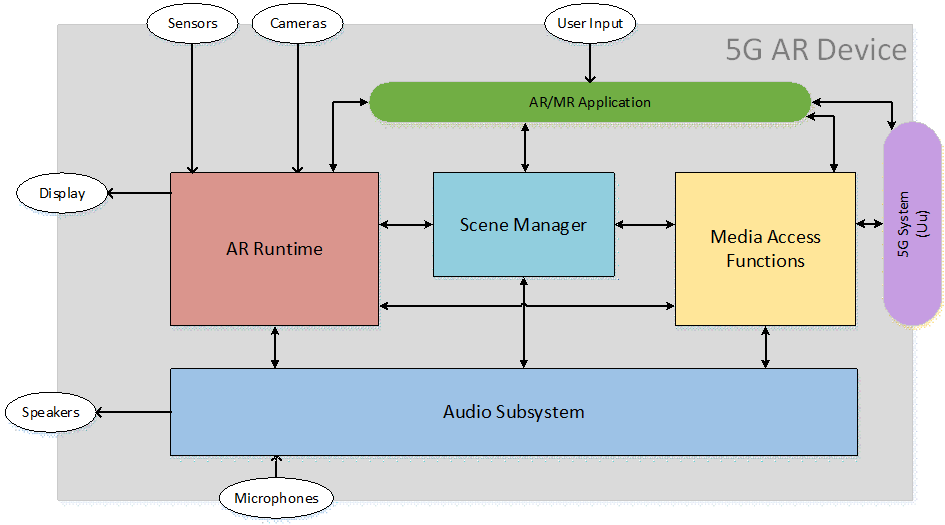
Figure 8.9-1: Immersive service architecture with audio subsystem - monolithic block
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
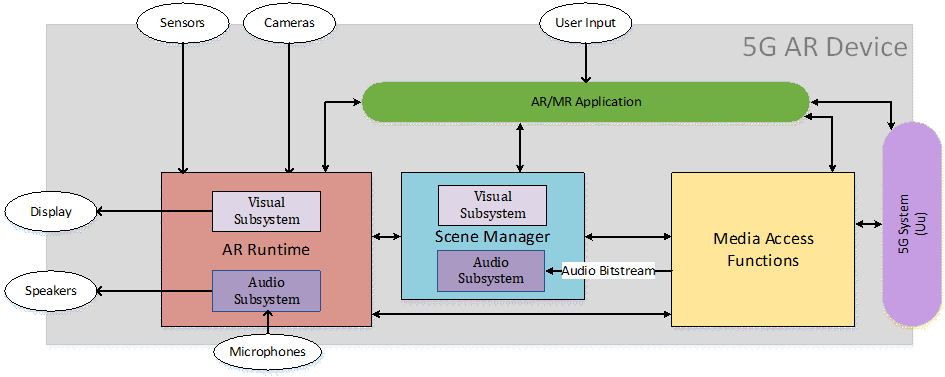
Figure 8.9-2: Immersive service architecture with audio subsystem - integrated decoding/rendering
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
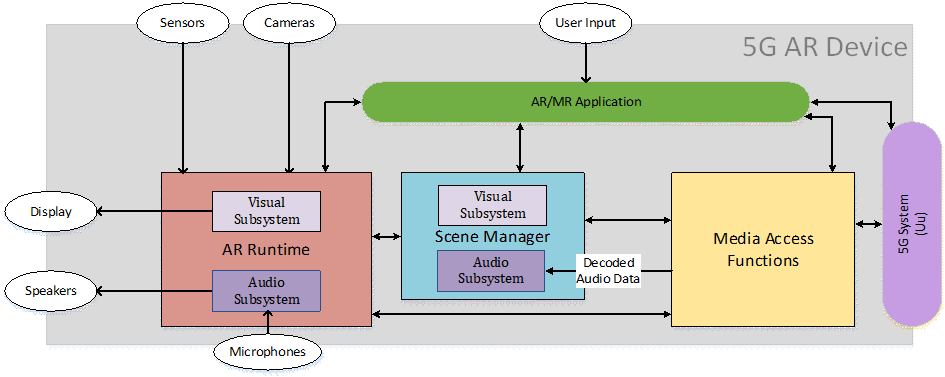
Figure 8.9-3: Immersive service architecture - separated audio decoding and rendering
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
Isolation of the audio path from the rest of the immersive scene and the other media types as in Figure 8.9-1 may be an issue. A single XR anchor space should ideally be used by the XR scene manager, similarly as a shared spatial system across audio and video was established for VR in TS 26.118.
8.9.2 Considerations on split rendering (EDGAR-based UE) |R18| p. 100
In the split rendering case, audio quality including end-to-end delay should ideally be preserved as compared to non-split rendered case. There is currently no codec / payload type specified in 3GPP to transport (decoded) spatial audio from the edge or cloud to an AR device for split rendering. The required characteristics (e.g., audio format, bit rate, frame length) of such a codec / payload type have to be defined to ensure adequate performance. The input audio format (e.g., channel-based, scene-based, object-based audio, MASA or combinations) may typically have to be preserved in the encoding-decoding process together with the associated metadata structure (when present in the audio input) to allow full rendering control, as expected from content creation.
![]()
![]()
![]()