Content for TR 26.998 Word version: 18.0.0
0…
4…
4.2…
4.2.2…
4.2.2.2
4.2.2.3
4.2.2.4
4.2.3…
4.3…
4.4…
4.5…
4.6…
4.6.4…
4.6.5…
4.6.8…
5
6…
6.2…
6.2.4…
6.2.4.2
6.2.5…
6.3…
6.3.4…
6.3.4.2
6.3.5…
6.4…
6.4.4
6.4.5…
6.5…
6.5.4
6.5.5
6.5.6…
6.6…
6.6.4
6.6.5…
7…
8…
8.9
9
A…
A.2
A.3…
A.4
A.5
A.6
A.7…
4.4 AR content formats and codecs
4.4.1 Overview
4.4.2 Scene Graph and Scene Description
4.4.3 Metadata
4.4.3.1 User pose information
4.4.3.2 Camera Parameters
4.4.4 Media Formats/Primitives in AR Scenes
4.4.5 Compression Formats
4.4.5.1 Elementary stream
4.4.5.2 Storage and Delivery Formats
4.4.6 Multiple Media Decoders management and coordination
4.4.7 XR Spatial Description
4.4.7.1 Overview
4.4.7.2 Camera and sensor information
4.4.7.3 Visual features, Keyframes and Spatial Maps
4.4.7.4 Spatial Anchors and Trackables
...
...
4.4 AR content formats and codecs p. 30
4.4.1 Overview p. 30
A 5G AR/MR application provider offers an AR/MR experience to a 5G UE using an AR/MR application and 5G System and media functionalities. AR/MR content is typically agnostic to a delivery architecture and consists of one or more AR/MR objects, each of which usually corresponds to an immersive media type in clause 4.4.4 and may include their spatial and temporal compositions. The delivery of an immersive media adaptive to device capability and network bandwidth may be enabled by a delivery manifest in clause 4.4.5. Processing of AR/MR functions in 5GMS AS may require additional metadata in clause 4.4.3 to properly recognize user's pose and surroundings.
AR/MR functions include encoding, decoding, rendering and compositing of AR/MR object, after which localization and correction is performed based on the user's pose information.
STAR-based architecture has both basic AR functions and AR/MR functions on the device. EDGAR-based architecture has only basic AR functions on the device.
Since AR/MR functions are on-device for the STAR-based architecture, immersive media including 2D media is considered as the input media for the architecture.
Examples of immersive media are 2D/3D media such as overlay graphics and drawing of instructions (UC#16 in Annex A.1), 3D media such as furniture, a house and an animated representation of 3D modeled person (UC#17 in Annex A.2), a photorealistic volumetric video of a person (UC#18 in Annex A.3), a 3D volumetric representation of conference participants (UC#19 in Annex A.4), 2D video, and volumetric information and simple textual overlays (UC#20 in Annex A.5).
For the EDGAR-based architecture, basic AR functions are on-device therefore 2D media and additional information (such as depth map) generated from immersive media renderer are considered as the input media for basic AR functions. A rasterized and physically-based rendering (PBR) image is an example of 2D media.
A study into the existing technologies to be considered as inputs to each function and device type are identified and presented as a non-exclusive list below.
- several visual media representation formats were documented in clause 4.4.4.
- several delivery manifests were documented in clause 4.4.5.
- several scene description formats were documented in clause 4.4.2.
- metadata such as user pose information and camera information were documented in clause 4.4.3.
- management and coordination of multiple media decoders are documented in clause 4.4.6, respectively.
4.4.2 Scene Graph and Scene Description p. 30
A scene description may correspond to an AR/MR content. A volumetric media containing the primitives ranging from one vertex to a complex object may be described by a scene description. For the use cases listed in Table 5-1, scene description is useful to locate AR/MR objects in user's world. A scene description typically has a tree or a graph structure which of each leaf represents a component of a scene. A primitive or a group of primitives are referenced as a leaf node of the scene tree. A skeleton to allow for motion rigging or an animation of motion of the skeleton in time may present an animation of volumetric presentation.
- Formats for scene description Khronos glTF2.0 and MPEG Scene description (ISO/IEC 23090-14) are examples of scene description technologies. They have a tree structure and internal/external resource references. There are many types of leaf of the tree. For example, a Node is one type of leaf under a Scene. A node may have a Camera as a subsidiary leaf. The node with camera represents one of the rendering frustum/viewport to be used by a scene renderer (i.e., immersive media renderer). Any translation/rotation/scaling of the node affects position and direction of its subsidiary, in this example, a camera. A node with mesh may be used as an anchor that represents AR object with its location and direction in geometric space. MPEG Scene description is an extension of glTF2.0. It is extended to support MPEG immersive media. MPEG_media and MPEG_scene_description are the major changes to provide support of media access link including manifest, and temporal update of the scene description itself.
4.4.3 Metadata p. 31
4.4.3.1 User pose information p. 31
User's position may be represented as a geolocation with longitude and latitude. The position may also be represented as a point in a scene. The scene may be represented as a bounding box on a geometry which represents the user's real environment. When an AR/MR device reports the user position to obtain a split rendering of the immersive media from a server, the device calculating the user pose is expected to be either a geolocation, a point in a scene or a point in a user's geometry. Depending on the representation, the server is assumed to be aware of the underlying scene or the geometry. A device is expected to update whenever there is any change in the scene or the geometry through user interaction (e.g., rotating a scene by hand gesture) and/or SLAM (e.g., finer modelling of surrounding environment).
A direction may be represented with a rotation matrix, or roll, pitch, and yaw. The direction is relative to a scene/geometry and the scene/geometry has an origin and default direction of the three axes.
The device representing a user's pose moves continuously, and if the device is worn on the user's head, it is assumed that he or she frequently turns their head around. A set of position and direction information is only meaningful at a certain moment in time. Since the device reports the user pose at around a frequency of 1 KHz, any pose information would need to include a timestamp to specify when it was measured or created. A pose corrector (e.g., ATW and LSR) in a server may estimate the user's future pose, whilst a pose corrector in a device may correct the received rendered image to fit the latest user pose.
- Formats for user pose A position in Cartesian coordinate system may be represented by either X, Y and Z or by a translation matrix. A direction may be represented by a rotation matrix or by quaternions. OpenXR describes a possible format for user pose [4]. It consists of 4 quaternions for orientation and 3 vectors for position. Timestamp is represented by a 64 bit monotonically increasing nano-second-based integer.
4.4.3.2 Camera Parameters p. 31
Immersive media is captured by camera(s). The camera parameters such as focal length, principal points, calibration parameters and the pose of the camera all contribute in understanding the relevance between points in the volumetric scene and pixels in the captured image. Photogrammetry is the technology used to construct immersive media from a continuous capturing of images. Depth sensor-based cameras may be used to capture immersive media from one capturing of the volumetric scene
- Formats for camera information Camera intrinsic parameters may be represented by a camera matrix. Extrinsic parameters may be represented by a transform matrix.
4.4.4 Media Formats/Primitives in AR Scenes p. 32
An AR/MR object may be represented in a form of 2D media. One camera or one view frustum in a scene may return a perspective planar projection of the volumetric scene. Such a 2D capture consists of pixels with colour attributes (e.g., RGB).
Each pixel (a) may represent a measure of the distance between the surface of an AR object, point (A) and the camera centre. Conventionally, the distance is represented by the coordinate of the point on the z-axis obtained by the orthogonal projection of the point (A) on this axis, here denoted as the point (A'). The measured distance is thus the length of the segment (CA') as depicted in Figure 4.4.4-1.
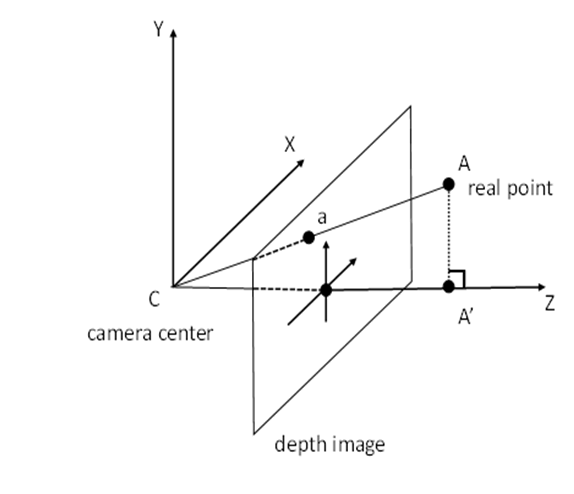
This convention is used for commercially available frameworks handling depth images such as the Microsoft Azure KinectTM SDK [7] and the Google ARCoreTM [8]. According to the documentation of the Azure KinectTM SDK, the depth sensor uses the Time-of-Flight (ToF) technique to measure the distance bewteen the camera and a light-reflecting point in the scene. The documentation further specifies that "these measurements are processed to generate a depth map. A depth map is a set of Z-coordinate values for every pixel of the image, measured in units of millimeters". Similarly, the Google ARCoreTM documentation explains that "when working with the Depth API, it is important to understand that the depth values are not the length of the ray CA itself, but the projection of it" onto the z-axis.
Additionally, sensor API may provide the image from the viewpoint of the depth sensor which is thus not aligned with the viewpoint of RGB camera which is necessarily few millimetres away due to physical constraints. In this case, an alignment operation is necessary in order to guarantee the correspondence between a pixel of the depth image and a pixel of the RGB picture. For instance, the Azure Kinect SDK provides the k4a_transformation_depth_image_to_color_camera() and k4a_transformation_color_image_to_depth_camera() functions which generate a depth image aligned with the colour picture and a colour image aligned with the depth image, respectively. More details and illustrations are provided in [9].
A depth map thus contains pixels with the distance attribute (e.g., depth). Distance is one-dimensional information and may be represented in an absolute/relative or linear/non-linear manner. Metadata to explain the depth map may be provided.
The capturing of a volumetric scene may also be expressed as an omnidirectional image in a spherical coordinate system. Equirectangular Projection (ERP) is an example of projection methods to map a spherical coordinate system into a cylindrical coordinate system. The surface of the cylindrical coordinate system is considered as 2D media.
Capturing of a volumetric scene may be further improved/elevated with hundreds of cameras in an array; High Density Camera Array (HDCA) or lenticular are methods to capture rays of light. Each point on surface of a volumetric scene has countless rays of colours in multiple different directions. Each position of a camera captures a different colour from the same point surface of the volumetric scene. 2D images from the camera array may be packed together to form a larger plenoptic image.
From another perspective, 2D media is the output of the immersive media renderer. One view frustum that represents the user's viewport is placed in a scene, and in turn, a perspective or an orthogonal projection of the volumetric media may be produced. To minimise motion sickness, a pose corrector function performs a correction of the 2D media at the last stage of presentation. The pose corrector may require additional information such as the estimated or measured user pose that was used for the rendering of the 2D media. For the case that the latest user pose does not match with the estimated user pose, additional information that provides knowledge on the geometry, such as a depth map, may be delivered from immersive media renderer.
Immersive media may be considered as an AR/MR object and may be used to provide an immersive experience to users. The immersive experience may include a volumetric presentation of such media. The volumetric presentation does not bind to a specific display technology. For example, a mobile phone may be used to present either the whole AR media, or a part of the AR media. Users may see a volumetric presentation of a part of the AR media augmented in real space. Therefore, immersive media includes not only volumetric media formats such as omnidirectional visual formatsERP image, 3D meshesPrimitives, point cloudsPrimitives, light fieldsPlenopotic image, scene description, and 3D audio formats, but also 2D video2D image as studied in TR 26.928.
- Formats for 2D media Still image formats may be used for 2D media. The 2D media may have metadata for each image or for a sequence of images. For example, pose information describes the rendering parameter of one image. The frame rate or timestamp of each image are typically valid for a sequence of such images.
- Primitives 3D meshes and point clouds consists of thousands and millions of primitives such as vertex, edge, face, attribute and texture. Primitives are the very basic elements in all volumetric presentation. A vertex is a point in volumetric space, and contains position information in terms of three axes in coordinate system. In a Cartesian coordinate system, X, Y, and Z make the position information for a vertex. A vertex may have one or more attributes. Colour and reflectance are typical examples of attributes. An edge is a line between two vertices. A face is a triangle or a rectangle formed by three or four vertices. The area of a face is filled by interpolated colour of vertex attributes or from textures.
4.4.5 Compression Formats p. 33
4.4.5.1 Elementary stream p. 33
An elementary stream is an output of a media encoder. Immersive media and 2D media in clause 4.4.4 have relevant technologies to encode each media format as follows.
- 2D Video codecs There are differences in terms of context of 2D media, such as RGB image versus depth map image, one planar perspective camera image versus ERP, or one camera image versus HDCA plenoptic image. Such differences may be considered in the proper encoder/decoder coding tools. In general, 2D video codecs may encode 2D media types listed in clause 4.4.4. AVC and HEVC are industry wide examples of 2D video codecs.
- MPEG OMAF (Omnidirectional MediA Format) OMAF consists of two parts; the first part is a pre-processing which includes a packing and projection of spherical volumetric media onto a 2D image, and the second part is an encapsulation of the compressed 2D frame packed image with metadata signalling the projection. For the compression of the 2D images, 2D video codecs may be considered and the pre-processing operations are agnostic to specific 2D codec technology.
- MPEG V3C and V-PCC V3C and V-PCC consists of two parts; the first part is a pre-processing which includes the decomposition of a part of the volumetric media into the planar projection, a patch, of different characteristics such as texture, geometry and occupancy. The second part is an encoding of 2D patch packing images, with metadata for signalling the decomposition. For the encoding of the 2D images, 2D video codecs may be considered and the pre-processing operations are agnostic to specific 2D codec technology.
- MPEG G-PCC G-PCC divides volumetric media into multiple sub-blocks. Triangle (Trisoup) or leaf (Octree) are used as the units of the divisions. A volumetric media is subdivided recursively until no more sub-blocks are left. The dimension (or level) of the tree is relatively large, such as 224. Tools including arithmetic encoding are used to encode all the tree information into the bitstream.
4.4.5.2 Storage and Delivery Formats p. 34
An encapsulation format encapsulates an elementary stream with its coding structure information and metadata information. ISOBMFF (ISO based Media File Format, ISO/IEC 14496-12) is one of encapsulation format technology. DASH initialization/media segment and CMAF track are the extensions of ISOBMFF for both adaptive streaming and storage purpose. They are extended to provide partial access of a media fragment on time axis.
A delivery manifest provides a description of media service consisting of multiple media components such as video and audio. Adaptation to device capability or network bandwidth is key features of a delivery manifest. In a delivery manifest, there is a group of multiple different encodings of the same media component context with the description of the encoding variations. An encapsulation format for an adaptive streaming is used to allow temporal access of media fragment to enable adaptive switching of a group of different encodings. MPD (Media Presentation Description) for DASH is one of delivery manifest for the purpose.
- File formats for Primitives OBJ, PLY, and GPU command buffer in OpenGL-based languages (e.g., glTF Buffer) are methods of encapsulating the primitives. A sequence of primitive files - such as multiple OBJs, PLYs or a set of GPU command buffers in a time may present an animation of volumetric presentation.
4.4.6 Multiple Media Decoders management and coordination p. 34
The use of hardware video decoding platform is essential for the decoding of AR/MR content when it comes to power consumption, fast and scheduled decoding as well as battery usage. Modern hardware video decoding platform typically offer the capability to instantiate multiple decoders of the same media type at the same time and run multiple decoding instances in parallel. A typical example is the decoding of different components of the same AR/MR object, or the presentation of multiple objects in a scene. As a result, AR/MR application typically runs several decoder instances, in some cases using the same codec for different instances, in others different codecs for different streams. Note that this issue not only exists for video, but for any media type, in particular also for object-based audio. Under this high demand, there may be a resource competition and scheduled issues for the hardware decoding platform.
From an application perspective, there are different cases as well. There may exist cases for which even several applications are competing for the hardware decoding platform, for example an application renders a scene, but other applications provide overlays and notifications on top of the existing scene. A possible solution is to handle the coordination at the operating system level by setting priority to each application.
However, a single AR/MR application accessing and managing several decoding instances is a more typical and prominent case. It is thus important that the performance of the different decoder instances running is in line with the expectations and the needs of the AR/MR applications such that the AR/MR applications may optimise the usage of the hardware decoding platform when possible.
The first question from the AR/MR application point of view is to determine the number of decoder instances to instantiate. To this end, the AR/MR application may determine the number of AR/MR objects to be presented as well as the number of elementary streams contained in each AR/MR object. The hardware decoding platform is typically exposing a capability query API which lists the supported codec. This information enables the AR/MR application to calculate how many AR/MR objects may be simultaneously decoded and with which quality. In addition, there may be cases wherein different elementary streams from the same AR/MR object may be jointly decoded as part of a single elementary stream hence streamlining the rest of the pipeline by effectively decreasing the number of decoder instances and output buffers needed. When this is the case, the AR/MR application may instruct the hardware decoding platform to merge those input elementary streams.
At runtime, the AR/MR application expects the decoded frames for each AR/MR object to be ready at the same point in time so that further processing of this AR/MR object may happen without loss of frames or delay introduced due to buffering. However, the concurrent decoder instances may exhibit different performance in terms of decoding delay for each frame. Therefore, it is useful for the AR/MR application to be able to signal to the hardware video decoding platform that certain decoder instances form a group that expected to be treated collectively in terms of output synchronisation.
4.4.7 XR Spatial Description p. 35
4.4.7.1 Overview p. 35
XR Spatial Description is a data structure (typically organized in a graph) describing the spatial organisation of the real world using:
- Visual features, keyframes and spatial maps as described in more details in clause 4.4.7.3.
- Spatial anchors and trackables as described in more details in clause 4.4.7.4.
- Camera parameters as defined in clause 4.4.3.2
4.4.7.2 Camera and sensor information p. 35
In this clause we provide an overview of different sensors that may provide input data for spatial compute AR functions. All device-captured data require a common timeline and a common coordinate system in order to be meaningful for XR Spatial Compute processing. If the data is processed in the networked, such time and spatial synchronization information is expected to be maintained.
AR Glasses typically include multiple cameras (for example one device supporting 7 cameras) to build precise motion tracking and gesture recognition. Generally, these camera feeds are processed on the device, but they may be sent across the network to support spatial compute functions. Different cameras exist on a single device, namely
- Monochrome image capture cameras,
- RGB image capture cameras,
- Infrared capture cameras.
4.4.7.3 Visual features, Keyframes and Spatial Maps p. 36
Visual features, keyframes, and spatial maps are used for mapping the real world, typically as part of the SLAM process.
Visual features are characteristics of real-world elements that are searched, recognized and tracked in 2D images captured by the AR device as the user moves in a real environment. These images provide a view of the same real world elements, captured from different positions (as indicated by the camera parameters attached to them) from a single moving camera or multiple cameras. Visual features are generally extracted from points that are recognizable in multiple images.
From the captured images of the real world, keyframes that include one or multiple visual features may be stored for later use. Visual features from the captured frames may be matched by comparing those frames with keyframes available to the AR Runtime in order to support the SLAM process. Keyframes have attached camera information defined in 4.4.3.2 to triangulate 3D points correctly from multiple cameras. These 3D points, triangulated from matching visual features are called spatial features.
Finally, a spatial map may be generated from keyframes and their matched visual features. A spatial map is, thus, a digital representation of the real world surrounding users consisting of at least one spatial feature cloud, e.g., 3D points (vector of 3 floats) with their associated descriptors such as SIFT [59], SURF [60], or ORB [61]. The geometrical part of the spatial map may be represented as a sparse or dense point cloud or a mesh. The mapping process may be performed either at runtime or offline. The spatial map is then used at runtime to relocalize and thus register the AR device by matching the visual features extracted from the current captured frames with spatial features stored in the spatial map. The spatial mapping approach described herein is one of well-known keyframe-based SLAM techniques [58].
The descriptors of features, whether visual or spatial, are generally vectors of numbers (e.g., vector of 128 floats for SIFT, vector of 64 floats for SURF, vector of 32 integers for ORB). Note that other features such as 3D segments (e.g., a 3D starting point and a 3D ending point) may also be used. During the localization process, the visual features extracted from the current frame, captured by the device, are matched with the spatial features of the map, resulting in 2D-3D correspondences used to estimate the pose of the cameras. However, since the 2D-3D matching process consists of comparing the descriptors of visual features extracted from the current image and those of the spatial features of the map, the complexity may quickly increase for maps containing several hundred thousand or even millions of spatial features. To accelerate the 2D-3D matching process, a spatial map typically also includes the following metadata:
- Information required for keyframe retrieval. For example, a keyframe retrieval uses Bag-Of-visual-Words (BoW) model. In this case, the information consists of the vocabulary of the BoW model and corresponding descriptor for each keyframe (vector of occurrence counts of a vocabulary in the keyframe). Depending on the visual descriptor used, the vocabulary size is usually a 10-100 MByte, and this vocabulary may be reused.
- The visual features for each keyframes (e.g. 2D points with their associated descriptors such as SURF, SIFT, ORB represented by a vector of numbers). The number of features extracted per keyframe varies between 200 and 1000.
- A vector pair (identifier of the visual features, identifier of the spatial features) that matches the visual features of keyframes with the spatial features of the spatial feature cloud.
- Matching the closest keyframe to the current frame by retrieving it with the BoW model
- Matching the visual features between the current frame and the retrieved keyframe
- Matching the visual features between the current frame and spatial feature cloud (knowing matches between visual features of the keyframes and spatial features of the spatial feature cloud)
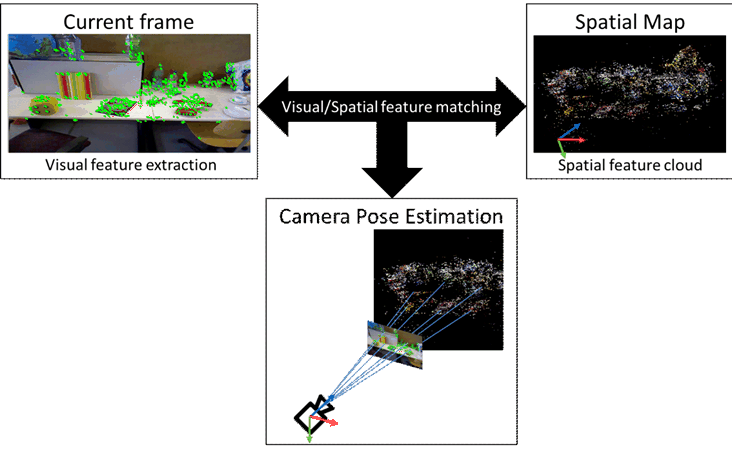
Figure 4.4.7.3-1: Camera pose estimation by features matching between a 2D captured frame and a spatial map
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
4.4.7.4 Spatial Anchors and Trackables p. 37
AR objects are positioned in reference to the real world (e.g., placing a vase on a table) using spatial anchors and trackables.
A spatial anchor provides a fixed position and orientation in the real world based on a common frame of reference that may be used by multiple AR devices. Spatial anchors are also used independently of other spaces in case global coordinates are available to the device. In this case, the anchors are treated as global anchors as they have global coordinates for which positions are determined.
However, in many cases an accurate global coordinate system is not available. In this case, spatial anchors refer to trackables for accurate positioning relative to the physical space. Trackables are elements of the real world for which features (visual or non-visual) are available and/or could be extracted. A trackable may for example be a spatial map that defines a full environment composed of floor walls and furniture in the real world consisting of several 3D points with visual features. However, there are other types of trackables, for example:
- A controller with LEDs that may be tracked by an AR headset's vision sensor. The feature in this case is the constellation of LEDs.
- A fiducial marker that is detected as a black and white pattern by an AR device vision sensor. The feature in this case is the black and white pattern.
- Hands visible through an AR headset's vision sensor. The feature is a learnt model for hands.
![]()
![]()
![]()