Content for TR 26.928 Word version: 17.0.0
0…
4…
4.1.2…
4.2…
4.3…
4.4…
4.5…
4.6…
4.6.7
4.7…
4.9…
5…
6…
7…
8
A…
A.4…
A.7…
A.10…
A.13
A.14
A.15
A.16…
A.19…
A.22…
A.15 Use Case 14: 6DOF VR conferencing p. 107
Use Case Name
6DOF VR conferencing
Description
The use case was initially described in TR 26.918 as Virtual Meeting Place:
The main idea here is to create a virtual world where people can meet and interact anonymously through their avatars with other people. A user would be able to move freely in the virtual world (6 DOF) and mingle with different groups of people depending for example on the discussion they are having. In this scenario, the user would be able to speak to other users in his/her immediate proximity and obtain a spatial rendering of what the other users in his/her immediate proximity are saying and would hear them from the same relative positions they have to him/her in the virtual world.
Below follows a more detailed description both of the physical scenario underlying the use case and the created virtual scenario.
1. Physical scenario
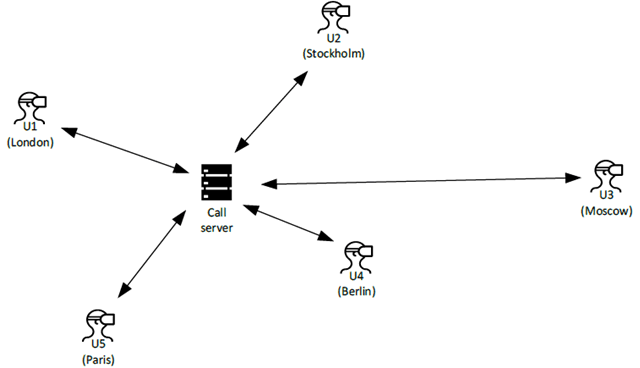
The physical VR conference scenario is illustrated in Fig. 1. Five VR conference users from different sites are virtually meeting. Each of them is using VR gear with binaural playback and video playback using an HMD. The equipment of all users supports movements in 6DOF with corresponding headtracking. The UEs of the users exchange coded audio up- and downstream with a VR conference call server. Visually, the users are represented through their respective avatars that can be rendered based on information related to relative position parameters and their rotational orientation.
2. Virtual scenario
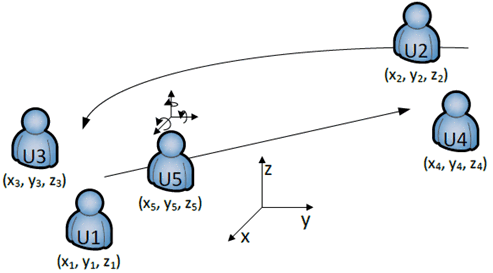
Fig. 2 illustrates the virtual conferencing space generated by the conference call server. Initially, the server places the conference users Ui, i=1…5, at virtual position coordinates Ki = (xi, yi, zi). The virtual conferencing space is shared between the users. Accordingly, the audio-visual render for each user takes place in that space. For instance, from user U5's perspective, the rendering will virtually place with the other conference participants at the relative positions Ki - K5, i≠5. For example, user U5 will perceive user U2 at distance |Ki - K5| and under the direction of the vector (Ki - K5)/|Ki - K5|, whereby the directional render is done relative to the rotational orientation of U5. Also illustrated in Fig. 2 is the movement of U5 towards U4. This movement will affect the position of U5 relative to the other users, which will be taken into account while rendering. At the same time the UE of U5 sends its changing position to the conferencing server, which updates the virtual conferencing space with the new coordinates of U5. As the virtual conferencing space is shared, users U1-U4 become aware of moving user U5 and can accordingly adapt their respective renders. The simultaneous movement of user U2 works according to corresponding principles.
Categorization
Type: VR
Degrees of Freedom: 6DoF
Delivery: Interactive, Conversational
Media Components: Audio-only, Audio-Visual
Devices: VR gear with binaural playback and HMD video playback, Call server
Preconditions
The described scenario relies on a conference call server.
Similar scenarios can be realized without a server. In that case, the UEs of all users need to be configured to share their encoded audio and their 6DOF positional and rotational information with the UEs of all other users. Each UE will further allow simultaneous reception and decoding of audio bitstreams and 6DOF attributes from the UEs of all other users.
Specific minimum preconditions
UE with render capability through connected HMD supporting binaural playback.
Mono audio capture.
6DOF Position tracking.
Conference call server:
Maintenance of participant position data in shared virtual meeting space.
Media preconditions:
Audio:
The capability of simultaneous spatial render of multiple received audio streams according to their associated 6DOF attributes.
Adequate adjustments of the rendered scene upon rotational and translational movements of the listener's head.
Video/Graphics:
Support of simultaneous graphics render on HMDs of multiple avatars according to their associated 6DOF attributes, including position, orientation, directivity.
Media synchronization and presentation format control:
Required for controlling the flow and proper render of the various used media types.
System preconditions:
A metadata framework for the representation and transmission of positional information of an audio sending endpoint, including 6DOF attributes, including position, orientation, directivity.
Requirements and QoS/QoE Considerations
QoS: conversational requirements as for MTSI, using RTP for Audio and Video transport.
Audio: relatively low bit rate requirements, that will meet conversational latency requirements.
Video/Graphics: no particular QoS requirements since graphics synthesis can be done locally at each rendering UE based on the received 6DOF attributes of the audio elements corresponding to the participants.
QoE: Immersive voice/audio and visual graphics experience.
The described scenario provides the users with a basic 6DOF VR meeting experience. Quality of Experience of the audio aspect can be enhanced if the user's UEs not only share their position coordinates but also their rotational orientation. This will allow render of the other virtual users not only at their positions in the virtual conference space but additionally with proper orientation. This is of use if the audio and the avatars associated with the virtual users support directivity, such as specific audio characteristics related to face and back.
Feasibility
The following capabilities and technologies are required:
UE with render capability through connected HMD supporting binaural playback.
Mono audio capture.
6DOF position tracking.
It is concluded that a service offering an experience as the described scenario is feasible with today's technology. The identified preconditions as well as the provided considerations on QoS/QoE do not suggest a feasibility barrier, given the technologies widely available and affordable today.
Potential Standardization Status and Needs
Requires standardization of at least a 6DOF metadata framework and a 6DOF capable renderer for immersive voice and audio.
The presently ongoing IVAS codec work item will provide an immersive voice and audio codec/renderer and a metadata framework that may meet these requirements.
Also required are suitable session protocols coordinating the distribution and proper rendering of the media flows.
![]()
![]()
![]()