Content for TR 22.856 Word version: 19.2.0
1…
5…
5.2…
5.3…
5.4…
5.5…
5.6…
5.7…
5.8…
5.9…
5.10…
5.11…
5.12…
5.13…
5.14…
5.15…
5.16…
5.17…
5.18…
5.19…
5.20…
5.21…
5.22…
5.23…
5.24…
5.25…
5.26…
5.27…
5.28…
6
7…
7.2
8
A
B
C…
5.26 Use Case on IMS-based 3D Avatar Call Support for Accessibility Use Case
5.26.1 Description
5.26.2 Pre-conditions
5.26.3 Service Flows
5.26.4 Post-conditions
5.26.5 Existing feature partially or fully covering use case functionality
5.26.6 Potential New Requirements
...
...
5.26 Use Case on IMS-based 3D Avatar Call Support for Accessibility Use Case p. 74
5.26.1 Description p. 74
3GPP has long standardized functionality to support availability of communication for users with disabilities. Global Text Telephony [56] provides a character-by-character text conversation to enable Global Text for those who rely on it, even for emergency service access. With the advent of speech recognition, it is possible to encode audio calls into text and text can be converted to speech. This kind of conversion goes a long way to achieve ITU-T SG16's Total Conversation vision: "Total Conversation is an ITU-T defined concept that encompasses voice telephony, video telephony and text telephony. The idea is that it gives everyone the chance to communicate with one another regardless of whether they are hearing, hearing impaired or deaf." [57]
There are a number of additional valuable scenarios that could be enabled through the use of IMS 3D Avatar Call, as described in 5.11.
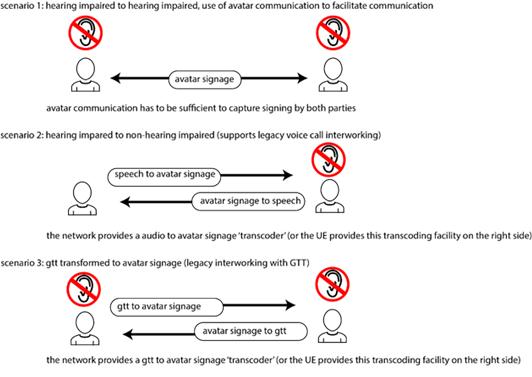
In scenario 1, above, a hearing-impaired user communicates with another using signage. Each user's gestures as well as facial expression and movements are captured by sensors (e.g. these sensors could be part of the terminal equipment) and transformed into an avatar encoding before transmission to the conversational partner. The experience of both parties is natural, and the user experience should resemble that of a video call, albeit with 'idealized lighting and contrast' due to the animation.
In scenario 2, one person speaks while the other signs. The signage of the person on the right is captured as described in scenario 1, but in addition it is analyzed. Research results indicate the likelihood that it will soon be possible to reliably use AI-based programs to capture signage to generate text. [57] It is clear that text to speech is possible. Thus for the user on the left, they can see the person on the right signing and receive an audio rendering of the text they generate.
The speech of the user on the left can be converted to text by means of voice recognition. There is extensive research into text to signage as well as some commercial products already available in this area. It is therefore possible for the user on the right to both see the user on the left speaking, as well as an avatar providing signage, or even an avatar rendering of the user on the left performing signage.
In scenario 3, one of the users may not be able to use IMS 3D Avatar call, e.g. they use terminal equipment without this support. In this case, the user on the left enters text and this is rendered as an avatar signing for the user on the right, if this is desired. The user on the right can express herself using signing, which is captured as text (as described for scenario 2) and sent as GTT text media to the user on the left.
One element is currently not possible with text conversion to other media, be it speech or generated avatar media of signage: the timing and emotions expressed in the communication. As part of scenario 3, we consider the possibility of capturing specific text conventions to indicate speech pauses or emotions.
An additional consideration is that the display equipment used to present the IMS 3D Avatar call may either be a UE itself or a separate monitor that the UE is able to use or is available through the display connected another UE, as by Inter-Device Connectivity (a feature of IMS.)
Finally, the possibility to support a communicating user that is 'software generated' is supported well by this use case. In this case, a variant of scenario 2 could be used where the user on the left is in fact an automated customer support centre representative. The computer-generated speech is rendered as signage to the user on the right, and the signage of the user on the right is rendered as speech to the software-based customer service party.
5.26.2 Pre-conditions p. 76
Both communicating parties AeCha, Bharathi and Carlos have a mobile subscription with PLMNs Absolute Telecom (PLMN A) and Benefit Wireless (PLMN B) and Celestial Cellular (PLMN C).
Both Arndt and Berndt have UEs that support sensors capable of capturing their facial expressions and movements as well as gestures sufficiently for this use case. They also are able to set their terminal equipment down so they have free hands (either on a tripod or table, etc.) Carl has a UE that is only capable of voice calls.
5.26.3 Service Flows p. 76
Scenario 1:




IMS 3D Avatar Call between two callers employing accessibility features and translation
AeCha calls Bharati. AeCha and Bharati use IMS 3D Avatar Call to communicate through sign language.
AeCha signs using Korean sign language. Bharathi signs using Hindi sign language. There are many forms of sign language in the world that are not mutually comprehensible internationally, and we assume that AeCha and Bharathi would not be able to understand each other's signage directly.
There are a set of services available in the communication channel between AeCha and Bharathi that enable the two of them can communicate.
Figure 5.26.3-1: IMS Avatar Call with Services for Signage to Text and Text Translation
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
AeCha's signing is captured by the sensors and encoded as Avatar Codec, capturing her use of Korean sign language. In the network, the signage is transcoded into Korean text. The Korean text can be translated into English text. This text can then be used to generate Indian Sign Language (shown in the transcoding function in PLMN B).
It is acknowledged that the translation services included in this use case are not exact, however the possibility to communicate directly using signage, and even with the avatar of the corresponding party could be quite valuable.
The avatars seen by AeCha and Bharathi are a representation of the other party, as sufficient information is exchanged by the 5G system to enable the transcoders that produce the avatar codec in PLMN A and PLMN B to do so.
Scenario 2:
IMS 3D Avatar Call and Audio between two callers, with accessibility enhancements
Figure 5.26.3-2: IMS Avatar Call with Services for Signage to Text and Text to Voice
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
Carlos speaks. His speech is recognized (in a transcoder in PLMN C) and encoded as English Text. This text is transported as media. The text is transcoded (in PLMN B) to Indian sign language encoded in an avatar codec. Bharathi views an avatar signing, using Indian sign language to represent Carlos' speech. The avatar is not a representation of Carlos as there are no sensors capturing Carlos, unless there is a means to configure the transcoder in PLMN B with the avatar information corresponding to Carlos' appearance. This is out of scope of this use case.
Bharathi signs, and this is captured in an Avatar codec that identifies her gestures, facial expression and movements. This is converted to English text in a transcoder function in PLMN B. The English text is sent as media to PLMN C, where a transcoder converts the text to speech. This speech is transported as audio media to Carlos, who hears a synthesized voice expressing the communication that Bharathi signed.
Scenario 3:
IMS 3D Avatar Call and GTT between two callers, with accessibility enhancements
Figure 5.26.3-3: IMS Avatar Call with Services for Signage to Text and Text to Voice
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
In this scenario, Carlos uses a GTT terminal to supply GTT media uplink. This media is converted in a transcoder to avatar codec representing signing in Indian sign language to Bharathi. The avatar is not a representation of Carlos as there are no sensors capturing Carlos, unless there is a means to configure the transcoder in PLMN B with the avatar information corresponding to Carlos' appearance. This is out of scope of this use case.
Bharathi signs, and this is captured in an Avatar codec that identifies her gestures, facial expression and movements. This is converted to GTT text in a transcoder function in PLMN B. The GTT media is delivered to Carlos, who reads text expressing the communication that Bharathi signed.
5.26.4 Post-conditions p. 77
In each of three scenarios one or both parties are able to sign and see signage in their native sign language in order to communicate with the other party. The possibility to interwork with legacy GTT terminals and legacy audio terminals is also supported.
5.26.5 Existing feature partially or fully covering use case functionality p. 77
The 5G system supports IMS which is able to handle diverse media, establish calls and support media codec transcoding services.
The 5G system supports GTT.
5.26.6 Potential New Requirements p. 77
[P.R-5.26.6-1]
The 5G system shall support the encoding of sensor data capturing the facial expression and movement and gestures of a person, in a standard form, such that as part of the avatar encoding
[P.R-5.26.6-2]
The 5G system shall support a set of transcoders from and to avatar representations e.g. between text, speech and avatar encoding.
[P.R-5.26.6-3]
The 5G system shall support the avatar transcoding functionality to control the appearance of the avatar based on the preferences of its associated user Examples of the controlled appearance could be for the avatar to express behavior, movement, affect, emotions, etc.
[P.R-5.26.6-4]
The 5G system shall support a set of transcoders to facilitate accessibility of avatar representation from and to GTT to control the appearance of the encoded avatar
[P.R-5.26.6-5]
The 5G system shall be able to collect charging information for transcoding services associated with IMS-based avatar call.
![]()
![]()
![]()