Content for TR 38.835 Word version: 18.0.1
1…
4…
5…
6
A
B…
B.1.2
B.1.3
B.1.4
B.1.5
B.1.6
B.1.7
B.1.8
B.1.9
B.1.10
B.2…
B.2.2
B.2.3
B.2.4
B.2.5
B.2.6
B.2.7
B.2.8
B.2.9
B.2.10
B.2.11
B.2.12
B.2.13
B.2.14
B.2.15
B.2.16
B.2.17
B.2.18
C…
4 Introduction to Extended Reality
4.1 Extended Reality Types
4.2 Human Perception and Tracking
4.3 Capture, Encoding and Delivery
4.3.1 Video
4.3.2 Audio
4.4 XR Engines and Rendering
4.5 Characteristics and Requirements
4.5.1 General
4.5.2 Video
4.5.3 Audio
4.5.4 Pose Information
...
...
4 Introduction to Extended Reality p. 9
4.1 Extended Reality Types p. 9
Extended Reality (XR) refers to all real-and-virtual combined environments and human-machine interactions generated by computer technology and wearables. XR is an umbrella term for different types of realities (see TR 26.918 and TR 26.928):
- Virtual reality (VR) is a rendered version of a delivered visual and audio scene. The rendering is designed to mimic the visual and audio sensory stimuli of the real world as naturally as possible to an observer or user as they move within the limits defined by the application. Virtual reality usually, but not necessarily, requires a user to wear a head mounted display (HMD), to completely replace the user's field of view with a simulated visual component, and to wear headphones, to provide the user with the accompanying audio. Some form of head and motion tracking of the user in VR is usually also necessary to allow the simulated visual and audio components to be updated in order to ensure that, from the user's perspective, items and sound sources remain consistent with the user's movements.
- Augmented reality (AR) is when a user is provided with additional information or artificially generated items or content overlaid upon their current environment. Such additional information or content will usually be visual and/or audible and their observation of their current environment may be direct, with no intermediate sensing, processing and rendering, or indirect, where their perception of their environment is relayed via sensors and may be enhanced or processed.
- Mixed reality (MR) is an advanced form of AR where some virtual elements are inserted into the physical scene with the intent to provide the illusion that these elements are part of the real scene.
4.2 Human Perception and Tracking p. 9
For providing XR experiences that make the user feel immersed and present, several relevant quality of experience factors have been collected (see TR 26.926). Presence is the feeling of being physically and spatially located in an environment. Presence is divided into 2 types: Cognitive Presence and Perceptive Presence. Cognitive Presence is the presence of one's mind. It can be achieved by watching a compelling film or reading an engaging book. Cognitive Presence is important for an immersive experience of any kind. Perceptive Presence is the presence of one's senses. To accomplish perceptive presence, one's senses, sights, sound, touch and smell, have to be tricked. To create perceptive presence, the XR Device has to fool the user's senses, most notably the audio-visual system. XR Devices achieve this through positional tracking based on the movement. The goal of the system is to maintain your sense of presence and avoid breaking it. Perceptive Presence is the objective to be achieved by XR applications.
The Human field of view (FoV) is defined as the area of vision at a given moment (with a fixed head). It is the angle of visible field expressed in degrees measured from the focal point. The monocular FoV is the angle of the visible field of one eye whereas the binocular FoV is the combination of the two eyes fields (see TR 26.918). The binocular horizontal FoV is around 200-220°, while the vertical one around 135°. The central vision, which is about 60°, is also called the comfort zone where sensibility to details is the most important. Although less sensitive to definition, the peripheral vision is more receptive to movements.
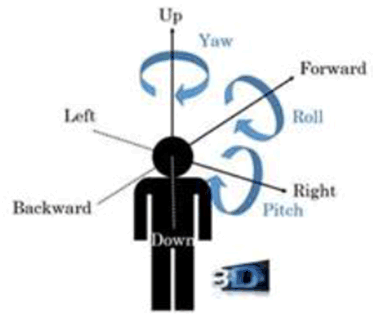
In XR, actions and interactions involve movements and gestures. Thereby, the Degrees of Freedom (DoF) describe the number of independent parameters used to define movement in the 3D space (see TR 26.928):
- 3DoF: three rotational and un-limited movements around the X, Y and Z axes (respectively pitch, yaw and roll). A typical use case is a user sitting in a chair looking at 3D 360 VR content on an HMD.

- 6DoF: 3DoF with full translational movements along X, Y and Z axes. Beyond the 3DoF experience, it adds (i) moving up and down (elevating/heaving); (ii) moving left and right (strafing/swaying); and (iii) moving forward and backward (walking/surging). A typical use case is a user freely walking through 3D 360 VR content (physically or via dedicated user input means) displayed on an HMD.
An XR View describes a single view into an XR scene for a given time. Each view corresponds to a display or portion of a display used by an XR device to present the portion of the scene to the user.
An XR Viewport describes a viewport, or a rectangular region, of a graphics surface. The XR viewport corresponds to the projection of the XR View onto a target display. An XR viewport is predominantly defined by the width and height of the rectangular dimensions of the viewport.
An XR Pose describes a position and orientation in space relative to an XR Space. An essential element of XR is the spatial tracking of the viewer pose.
4.3 Capture, Encoding and Delivery p. 10
4.3.1 Video p. 10
XR content may be represented in different formats, e.g. panoramas or spheres depending on the capabilities of the capture systems. Since modern video coding standards are not designed to handle spherical content. Projection is used for conversion of a spherical (or 360°) video into a two-dimensional rectangular video before the encoding stage. After projection, the obtained two-dimensional rectangular image can be partitioned into regions (e.g. front, right, left, back, top, bottom) that can be rearranged to generate "packed" frames to increase coding efficiency or viewport dependent stream arrangement.
There are mainly three approaches that can be considered for 360 video delivery (see TR 26.918):
- Single stream approach: the single stream approach consists in providing the full 360 video and showing the interesting part only. Solutions that lie within this group have the drawback that either they may not be scalable or they may impose a big challenge in terms of required network resources (high bitrate of high resolution video) and required processing at the client side (decode a very high resolution video).
- Multi-stream approach: the multi-stream approach consists of encoding several streams, each of them emphasizing a given viewport and making them available for the receiver, so that the receiver decides which stream is delivered at each time instance.
- Tiled stream approach: the tiled stream approach consists in emphasizing the current user viewport through transmitting non-viewport samples with decreased resolution. The tiles can be provided as one common bitstream (using motion-constrained HEVC tiles) or as separate video streams.
- Complex prediction structures are used that take into account application constraints, encoding complexity, latency and dynamic decisions in the encoding. This may result in irregularities, for example based on sequence properties. In particular for low-latency delivery with error resiliency, different flavours of encoding operations are in use, and the concept of I, P and B pictures is not generally applicable.
- All PDUs in a PDU Set are needed by the application layer to use the corresponding unit of information in some implementations; while in some others, receivers may use the data up to the first lost fragmentation unit to recover at least parts of the video data and apply error concealment afterward.
- Furthermore, in motion-compensated predicted video decoding, some frames refer to other frames based on the video encoding configuration but also based on dynamic operational decisions. As a consequence, a PDU Set may "depend" on previously received PDU Sets. However, such dependencies do not necessarily result in discarding dependent information units.
4.3.2 Audio p. 11
For Audio, we can distinguish channel-based and object-based representations (see TR 26.918):
- Channel-based representation using multiple microphones to capture sounds from different directions and post-processing techniques are well known in the industry, as they have been the standard for decades.
- Object-based representations represent a complex auditory scene as a collection of single audio elements, each comprising an audio waveform and a set of associated parameters or metadata. The metadata embody the artistic intent by specifying the transformation of each of the audio elements to playback by the final reproduction system. Sound objects generally use monophonic audio tracks that have been recorded or synthesized through a process of sound design. These sound elements can be further manipulated, so as to be positioned in a horizontal plane around the listener, or in full three-dimensional space using positional metadata.
4.4 XR Engines and Rendering p. 11
XR engines provide a middleware that abstracts hardware and software functionalities for developers of XR applications (see TR 26.928). Typical components include a rendering engine for graphics, an audio engine for sound, and a physics engine for emulating the laws of physics. In the remainder of this Technical Report, the term XR engine is used to provide any type of typical XR functionalities as mentioned above.
The processing of an XR engine is not exclusively carried out in the device GPU. In power and resource constrained devices, it can be assisted or split across the network through edge computing (see TR 22.842): the UE sends the sensor data in uplink direction to the cloud side in a real time manner and when the cloud side receives the sensor data, it performs rendering computing and produces the multimedia data and then sends back to the user devices for display. This is where NR can play an essential role.
4.5 Characteristics and Requirements p. 11
4.5.1 General p. 11
In general, the RTP layer can handle out-of-sequence reception of RTP packets, and some codecs even require it for good operations (instead of having to cope with increased delays to satisfy in-sequence delivery). Thus, a mode of operation where the lower-layers on the receiver side do not always enforce in-sequence delivery to upper layers is preferred (see S4aR230035 [17]).
Other than that, it is difficult to identify characteristics common for different XR applications since they heavily depend on the application choices, such as the application itself, the codec in use, the data formats and the encoding operation (see S4-220505 [13]). In particular, low-latency XR and cloud gaming video services such as Split-Rendering or Cloud Gaming typically would not use the traditional coding structure with a fixed Group of-Picture (GOP). In addition, the field of low-latency video delivery is undergoing heavy innovation and new coding methods may be established frequently. Thus, the traffic characteristics and requirements derived from the work done in SA4 (TR 26.926 and TR 26.928) and listed below, can only be used as a baseline when specific examples for XR traffic characteristics are needed - bearing in mind that they are not universally applicable for all XR applications.
4.5.2 Video p. 12
The frame rate for XR video varies from 15 frames per second up to 90 or even 120 frames per second, with a typical minimum of 60 for VR (see TR 26.918 and TR 26.926).
According to TR 26.918, the latency of action of the angular or rotational vestibulo-ocular reflex is known to be of the order of 10 ms or in a range from 7-15 milliseconds and it seems reasonable that this should represent a performance goal for XR systems. This results in a motion-to-photon latency of less than 20 milliseconds, with 10ms being given as a goal.
Regarding the bit rates, between 10 and 200Mbps can be expected for XR depending on frame rate, resolution and codec efficiency (see TR 26.926 and TR 26.928).
4.5.3 Audio p. 12
According to TR 26.918, due to the relatively slower speed of sound compared to that of light, it is natural that users are more accustomed to, and therefore tolerant of, sound being relatively delayed with respect to the video component than sound being relatively in advance of the video component. Recent studies have led to recommendations of an accuracy of between 15 ms (audio delayed) and 5 ms (audio advanced) for the synchronization, with recommended absolute limits of 60 ms (audio delayed) and 40 ms (audio advanced) for broadcast video.
4.5.4 Pose Information p. 12
To maintain a reliable registration of the virtual world with the real world, as well as to ensure accurate tracking of the XR Viewer pose, XR applications require highly accurate, low-latency tracking of the device at about 1kHz sampling frequency. The size of a XR Viewer Pose associated to time, typically results in packets of size in the range of 30-100 bytes, such that the generated data is around several hundred kbit/s if delivered over the network with latency requirements in the range of 10-20ms (see TR 26.928).
Repeatedly providing the XR Viewer Pose for the same display time may not necessarily return the same result (the prediction gets increasingly accurate as the information is closer to the time when a prediction is made) and there is a trade-off between providing several XR Viewer Pose for a display time and using the same XR Viewer Pose for several consecutive display times. However, it can be assumed that sending one XR Viewer Pose aligned with the frame rate of the rendered video may be sufficient, for example at 60fps (see S4-221626 [16]).
Pose information has to be delivered with ultra-high reliability, therefore, similar performance as URLLC is expected i.e. packet loss rate should be lower than 10E-3 for uplink sensor data - see S4-221626 [16].
![]()
![]()
![]()