Content for TS 26.118 Word version: 18.0.0
B Example External Binaural Renderer
B.1 General
B.2 Interfaces
B.2.1 Interface for Audio Data and Metadata
B.2.2 Head Tracking Interface.
B.2.3 Interface for Head-Related Impulse Responses
B.3 Preprocessing
B.3.1 Channel Content
B.3.2 Object Content
B.3.3 HOA Content
B.3.4 Non-diegetic Content
B.4 Scene Displacement Processing
B.4.1 General
B.4.2 Applying Scene Displacement Information
B.5 Headphone Output Signal Computation
B.5.1 General
B.5.2 HRIR Selection
B.5.3 Initialization
B.5.4 Convolution and Crossfade
B.5.5 Binaural Downmix
B.5.6 Complexity
B.5.7 Motion Latency
B Example External Binaural Renderer p. 78
B.1 General p. 78
Binaural rendering allows 3D audio content to be played back via headphones. The rendering is performed as a fast convolution of point sound source streams in the 3D space with head-related impulse responses (HRIRs) or binaural room impulse responses (BRIRs) corresponding to the direction of incidence relative to the listener. HRIRs will be provided from an external source.
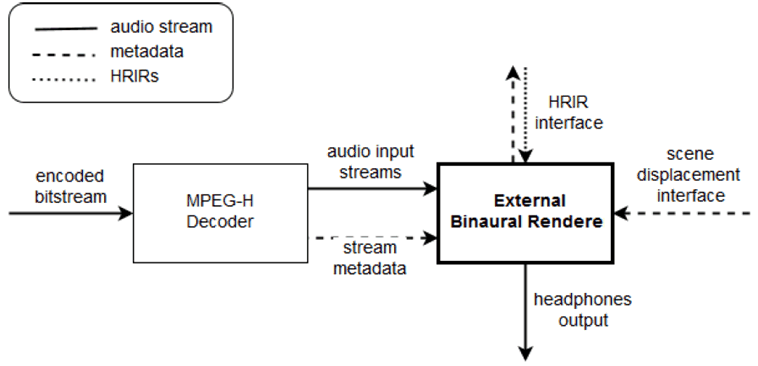
Figure B.1-1: High level overview of an external binaural renderer setup.
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
The renderer has three input interfaces (see Figure B.1-1): the audio streams and metadata from the MPEG-H decoder, a head tracking interface for scene displacement information (for listener tracking), and a head-related impulse response (HRIR) interface providing binaural impulse responses for a given direction of incidence. The metadata as described in clause B.3, together with the scene displacement information, is used to construct a scene model, from which the renderer can infer the proper listener-relative point source positions.
The audio input streams may include Channel content, Object content, HOA content. The renderer performs pre-processing steps to translate the respective content type into several point sources that are then processed for binaural rendering. Channel groups and objects that are marked a non-diegetic in the metadata are excluded from any scene displacement processing.
B.2 Interfaces p. 78
B.2.1 Interface for Audio Data and Metadata p. 78
The example external binaural renderer has an interface for the input of un-rendered channels, objects, and HOA content and associated metadata. The syntax of this input interface follows the specification of the External Renderer Interface for MPEG-H 3D Audio to output un-rendered channels, objects, and HOA content and associated metadata according to clause 6.1.4.3.6.5.
The input PCM data of the channels and objects interfaces is provided through an input PCM buffer, which first contains n_"chan,out" signals carry the PCM data of the channel content. These are followed by n_"obj,out" signals carrying the PCM data of the un-rendered objects. Then additional signals carry the n_"HOA,out" HOA data which number is indicated in the HOA metadata via the HOA order (e.g. 16 signals for HOA order 3). The HOA audio data in the HOA interface is provided in the ESD representation. The conversion from the HOA domain into the equivalent spatial domain representation and vice versa is described in ISO/IEC 23008-3 [19], Annex C.5.1.
The metadata for channels, objects, and HOA is received via the input interface once per frame and their syntax is specified in mpegh3da_getChannelMetadata(), mpegh3da_getObjectAudioAndMetadata(), and mpegh3da_getHoaMetadata() respectively, see ISO/IEC 23008-3, clause 17.10 [19]. The metadata and PCM data will be aligned to match each metadata element with the respective PCM frame.
B.2.2 Head Tracking Interface. p. 79
The external binaural renderer receives scene displacement values (yaw, pitch and roll) e.g. from an external head tracking device via the head tracking interface. The syntax is specified in mpegh3daSceneDisplacementData() as defined in ISO/IEC 23008-3 [19], clause 17.9.3.
B.2.3 Interface for Head-Related Impulse Responses p. 79
An interface is provided to specify the set of HRIRs used for the binaural rendering. These directional FIR filters will be input using the SOFA (Spatially Oriented Format for Acoustics) files format according to AES-69 [21]. The SimpleFreeFieldHRIR convention will be used, where binaural filters are indexed by polar coordinates (azimuth φ in radians, elevation Φ in radians, and radius r in meters) relative to the listener.
B.3 Preprocessing p. 79
B.3.1 Channel Content p. 79
Channel input content is converted into a corresponding set of point sources with associated positions using the loudspeaker configuration data included in mpegh3da_getChannelMetadata() and the associated PCM data obtained via the interface specified in clause B.2.1
B.3.2 Object Content p. 79
Object input content is converted into corresponding point sources with associated positions using the metadata included in mpegh3da_getObjectAudioAndMetadata() and the associated PCM data obtained via the interface specified in clause B.2.1
B.3.3 HOA Content p. 79
As specified in clause B.2.1 HOA content is input in the ESD representation together with the metadata included in mpegh3da_getHoaMetadata(). As a pre-processing step, the ESD representation is first converted into HOA coefficients. All coefficients associated with HOA of order larger than three are discarded to limit the maximum computational complexity.
B.3.4 Non-diegetic Content p. 79
Channel groups for which the gca_directHeadphone flag is set in mpegh3da_getChannelMetadata() are routed to left and right output channel directly and are excluded from binaural rendering using scene displacement data (non-diegetic content). Non-diegetic content may have stereo or mono format. For mono, the signal is mixed to left and right headphone channel with a gain factor of 0.707.
For each channel group it has to be checked in the mpegh3da_vgetChannelMetadata() if the gca_fixedChannelsPosition flag is equal to 0 or 1. A channel group with an associated 'gca_fixedChannelsPosition == 1' is included in the binaural rendering but excluded from the scene displacement processing according to clause B.4, i.e. its position is not updated.
For each object it has to be checked in the mpegh3da_getObjectAudioAndMetadata() if the goa_fixedPosition flag is equal to 0 or 1. An object with an associated 'goa_fixedPosition == 1' is included in the binaural rendering but excluded from the scene displacement processing according to clause B.4, i.e. its position is not updated.
B.4 Scene Displacement Processing p. 80
B.4.1 General p. 80
The position of each point source derived from the channels and objects input is represented by a 3-dimensional vector s ⃑_c in a Cartesian coordinate system. The scene displacement information is used to compute an updated version of the position vector s ⃑_c^' as described in clause B.4.2. The position of point sources that result from non-diegetic channel groups with an associated 'gca_fixedChannelsPosition == 1' or from non-diegetic objects with an associated 'goa_fixedPosition == 1' (see clause B.3.4) is not updated, i.e. s ⃑_c^' is equal to s ⃑_c.
B.4.2 Applying Scene Displacement Information p. 80
The vector representation of a point source s ⃑_c is transformed to the listener-relative coordinate system by rotation based on the scene displacement values obtained via the head tracking interface. This is achieved by multiplying the position s ⃑_c with a rotation matrix calculated from the orientation of the listener:
s ⃑_c^'=T_rot s ⃑_c
The determination of the rotation matrix T_rot is defined in ISO/IEC 23008-3 [19], Annex I.
For HOA content, the rotation matrix T_(rot,hoa) suited for rotating the spherical harmonic representation is calculated as defined in ISO/IEC 23008-3 [19], Annex I. After the rotation, the HOA coefficients are transformed back into the ESD representation. Each ESD component is then converted to the corresponding point source with its associated positional information. For the ESD components the position information is fixed, i.e. s ⃑_c^'=s ⃑_c , as the rotation due to scene displacement is performed in the spherical harmonic representation.
B.5 Headphone Output Signal Computation p. 80
B.5.1 General p. 80
The overall Scene Model is represented by the collection of all point sources with updated position s ⃑_c^' obtained from the rotated channels, objects, and the ESD components as well as the non-diegetic channels and objects for which 'gca_fixedChannelsPosition == 1' or 'goa_fixedPosition == 1'. The overall number of point sources in the Scene Model is denoted with C.
B.5.2 HRIR Selection p. 80
The position s ⃑_c^' of each point source in the listener-relative coordinate system is used to query a best-match HRIR pair from the set of available HRIRs. For lookup, the polar coordinates of the HRIR locations are transformed into the internally used cartesian coordinates and the closest-match available HRIR for a given point source position is selected. As no interpolation between different HRIRs is performed, HRIR datasets with sufficient spatial resolution should be provided.
B.5.3 Initialization p. 80
The HRIR filters used for binauralization are asynchronously partitioned and transformed into the frequency domain using a Fast FourierTransform (FFT). The necessary steps for each of the C HRIR filter pairs are as follows:
- Uniformly partition the length N HRIR filter pairs f_(c,L/R) (n) into P=⌈N/B⌉ filter partitions f_(c,p,L/R) (n) of length B.
- Zero-pad the filter partitions to length K.
- Transform all filter partitions into the frequency domain using real-to-complex FFT to obtain the P frequency domain filter pairs F_(c,p,L/R) (k), where k denotes the frequency index.
B.5.4 Convolution and Crossfade p. 81
Each audio block of a point source of the Scene Model is convolved with its selected HRIR filter pair for the left and right ear respectively. To reduce the computational complexity, a fast frequency domain convolution technique of uniformly partitioned overlap-save processing is useful for typical FIR filter lengths for HRIRs/BRIRs. The required processing steps are described in the following.
The following block processing steps are performed for each of the C point sources of the Scene Model:
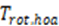 (see clause B.4.2).
(see clause B.4.2).
- Obtain a block of B new input samples x_c (n) of the point source c .
- Perform a real-to-complex FFT transforms of length K to obtain the frequency domain representation of the input X_c (k).
- Compute the frequency domain headphone output signal pair Y_(c,L/R) (k) for the point source c by multiplying each HRIR frequency domain filter partition F_(c,p,L/R) (k) with the associated frequency domain input block and adding the product results over all partitions.
- K samples of the time domain output signal pair y_(c,L/R) (n) are obtained from Y_(c,L/R) (k) by performing a complex-to-real IFFT.
- Only the last B output samples represent valid output samples. The K-B samples before are time-aliased and are discarded.
- In case of a HRIR filter exchange happens due to changes in the scene displacement, steps 3-5 are computed for both the current HRIR filter and the ones used in the previous block. A time-domain crossfade is performed over the B output samples obtained in step 5:
- y_(c,L/R) (n)=〖w_in (n)y〗_(c,L/R,current) (n)+ 〖w_out (n)y〗_(c,L/R,prev) (n)
-
The crossfade envelopes are defined as
to preserve a constant power of the resulting output signal.
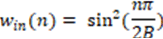
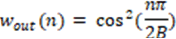
(see clause B.4.2).
B.5.5 Binaural Downmix p. 81
The rendered headphone output signal is computed as the sum over all binauralized point source signal pairs . In case that the metadata provided together with the audio data at the input interface (see X.3.1) includes gain values applicable to a specific channel group (gca_channelGain in mpegh3da_getChannelMetadata()) or objects (goa_objectGainFactor in mpegh3da_getObjectAudioAndMetadata()), these gain values are applied to the corresponding binauralized point source signal 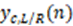 before the summation:
before the summation:
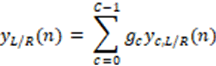 Finally, any additional non-binauralized non-diegetic audio input ('gca_directHeadphone == 1', see clause B.3.4) is added time-aligned to the two downmix channels.
Finally, any additional non-binauralized non-diegetic audio input ('gca_directHeadphone == 1', see clause B.3.4) is added time-aligned to the two downmix channels.
before the summation:
B.5.6 Complexity p. 82
The algorithmic complexity of the external binaural renderer using a fast convolution approach can be evaluated for the following computations:
| Convolution (clause B.5.4) |
|
| Downmix (clause B.5.5) |
|
| Filter Exchange and Crossfade (clause B.5.4) |
|
Additional computations are required for scene displacement processing (see clause B.4).
The total complexity per output sample can be determined by adding the complexity estimation for convolution and downmix and dividing by the block length B. In blocks where a filter exchange is performed, items 2-4 from the convolution contribute two times to the overall complexity in addition to the time-domain crossfade multiplications and additions (filter exchange items 2 and 3). The partitioning and FFT for the filter exchange, as well as the scene displacement, can be performed independent of the input block processing.
B.5.7 Motion Latency p. 82
The Scene Model can be updated with arbitrary temporal precision, but the resulting HRIR exchange is only done at processing block boundaries of the convolution. With a standard block size of B = 256 samples at 48 kHz sampling rate, this leads to a maximum onset latency of 5.3 ms until there is an audible effect of a motion of sources or the listener. In the following block, a time-domain crossfade between the new and the previous filtered signal is performed (see Convolution/Initialization), so that a discrete, instantaneous motion is completed after a maximum of two convolution processing blocks (10.6 ms for 512 samples at 48 kHz sampling rate). Additional latency from head trackers, audio buffering, etc. is not considered.
The rotation of the HOA content is performed at a block boundary resulting in a maximum latency of one processing block, until a motion is completed.
![]()
![]()
![]()