Content for TS 23.042 Word version: 18.0.0
4 Algorithms
4.1 Huffman Coding
4.2 Character Groups
4.3 UCS2
4.4 Keywords
4.5 Punctuation
4.6 Character Sets
...
...
4 Algorithms p. 8
The compression algorithm comprises a number of components that may be combined in a variety of configurations. The discrete algorithms are discussed in the following subclauses.
4.1 Huffman Coding p. 9
The base compression algorithm is a Huffman coder, whereby characters in the input stream are represented in the output stream by bit sequences of variable length. This length is inversely proportional to the frequency with which the character occurs in the input stream.
This is the only component of the whole compression algorithm that can be expected to be included in any implementation, all other components are optional.
There are two possible approaches here:
- the (de)coder can be "pre-loaded" with a character frequency distribution, thus improving compression rate for streams that approximate to this distribution; or
- the (de)coder can adapt the frequency distribution it uses to (de)code characters based on the incidence of previous characters within the input stream.
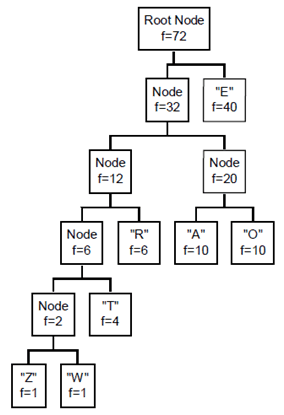
The tree represents the characters Z, W, T, R, A, O and E which have frequencies of 1, 1, 4, 6, 10, 10 and 40 respectively. The characters may be coded as variable length bit streams by starting at the "character node" and ascending to the "root node". At each stage, if a left hand path is traversed, a 0 bit is emitted and if a right hand path is traversed a 1 bit is emitted. Thus the infrequent Z and W would require 5 bits, whereas the most frequent character E requires just 1 bit. The resulting bit stream is decoded by starting at the "root node" and descending the tree, to the left or right depending on the value of the current bit, until a "character node" is reached.
It is a requirement that at any time the trees expressing the character frequencies shall be identical for both coder and decoder. This can be achieved in a number of ways.
Firstly, both coder and decoder could use a fixed and pre-agreed frequency distribution that includes all possible characters but as noted above, this use of "prior information" suffers when a given input stream has a significantly different character frequency distribution.
Secondly, the coder may calculate the character frequency distribution for the entire input stream and prepend this information to the encoded bit stream. The decoder would then generate the appropriate tree prior to processing the bitstream. This approach offers good compression, especially if the character frequency information may itself be compressed in some manner. Approaches of this type are common but the cost of the prepended information for a potentially small data stream makes it less attractive.
Thirdly, extend the algorithm such that although both coder and decoder start with known frequency distributions, and subsequently adapt these distributions to reflect the addition of each character in the input stream. One possibility is to have initial distributions that encompass all possible characters so that all that is required, as each input character is processed, is to increment the appropriate frequency and update the tree. However, the inclusion of all possible characters in the initial distribution means that the tree is relatively slow to adapt, making this approach less appropriate for short messages. An alternative is to have an initial distribution that does not include all possible characters and to add new characters to the distribution if, and when, they occur in the input stream.
To achieve the latter approach, the concept of a "special" character is required. A "special" character is one whose value is outside the range of the character set being used (e.g. 256 if the character set has a range 0 to 255). These characters therefore do not form part of the input stream being conveyed, but their existence in the compressed stream signals the need for the decoder to adjust its behaviour. Here a "special" character is used to signal that the following n bits (where n is a fixed value) represent a new character that needs to be added to the frequency distribution. In the example above this would be done by replacing the "character" node containing the character Z with a new node that had as its children the "character" nodes for Z and for the new character.
This is the approach taken here. It provides considerable flexibility, effectively enabling all of the foregoing approaches. The specific approach to be used for a given message is signalled in the header.
The algorithm uses an additional optimization in that 2 special characters are defined, one meaning that a 7-bit literal follows and the other for 8-bit characters. So for example:
- The initial tree can contain just the "new character follows" special character(s). In this case, the input stream "AAA" would result in: [1 bit = new character(7bit) special][7 bits = "A"][2 bits = "A"][1 bit = "A"]
- As can be seen from the above there is quite a high cost in adding a new character (the "special" plus literal). So if the initial tree contains a small subset of the generally most frequently used characters, the cost of character addition can be avoided for these characters.
- Given that we can signal in the header a specific initial frequency distribution, there is no reason why this distribution cannot contain all possible characters and frequency adaptation enabled or disabled as appropriate.
4.2 Character Groups p. 10
Character grouping is an optional component that can effect an increase in compression performance of the Huffman coder. This technique groups characters that may be expected to occur together within the input stream and signals transitions between the groups rather than each individual character.
The algorithm derives benefit by;
- reducing the need to add new characters to the frequency distribution; and
- using a smaller overall tree. For example, assume that there is no pre-loaded distribution and a stream comprised the characters "abcdefABCDEF".
4.3 UCS2 p. 10
Input streams comprising 16bit UCS2 information are handled in a manner similar to Character groups. Both coder and decoder maintain knowledge of "the current" Basic Multilingual Plane row for characters in the input stream and the row octet itself is then omitted from the output stream for sequences of characters within that row. Transitions between rows are signalled in the output stream by a "special" character.
Support for UCS2 is optional.
4.4 Keywords p. 11
The algorithm optionally supports the concept of dictionaries - essentially a list of key words or phrases of up to 255 characters in length. Dictionaries need to be known to both the coder and the decoder. The input stream is matched against entries in the dictionary and matching characters in the stream are replaced with a reference to the dictionary entry.
Again "special" characters are used to signal that the following sequence of bits describe a reference to a dictionary entry. So for example, if a dictionary contains the phrases "Please" and "meeting", an input stream "Please cancel the monthly meeting" would be rendered as:
[keyword special][10 bits = "Please"][.......][keyword special][10 bits = "meeting"]
Dictionary matches for long strings can result in very high compression rates.
4.5 Punctuation p. 11
The punctuation processor is distinct from the other algorithms in that it is non-symmetric so the decompressed stream may not be identical to the original. Its use is therefore mainly applicable to input streams comprising human readable sentences where it is sufficient to preserve the meaning of the content, but not the exact format. It is also applicable when the input stream is a "standard sentence" that is known to produce a symmetric result. The punctuation processor is applied before (on coding) and after (on decoding) any of the other algorithms. Its functions are:
- to remove leading and trailing spaces from the input stream;
- to replace repeated spaces within the stream with a single space;
- to remove (on coding) and insert (on decoding) spaces following certain punctuation characters;
- to decapitalize (on coding) and capitalize (on decoding) the first character of the stream, the first character following an appropriate punctuation character or a paragraph symbol and capitalized single character words such as "I";
- to remove (on coding) and insert (on decoding) a full stop if it is the last character of the stream.
4.6 Character Sets p. 11
The use of pre-loaded frequencies, key word dictionaries and the punctuation processor all require that a consistent character set is used by both coder and decoder. As there can be no assumption that the same character will be have the same value (or even be available) on the devices used to send and receive a compressed message, the algorithms are specified to operate on a known character set to which (prior to coding) and from which (post decoding) a device needs to convert an input stream to render it in the native character set of the device.
The handling of character sets is mandatory for all implementations.
![]()
![]()
![]()