Content for TS 23.040 Word version: 18.0.0
0…
3…
3.3…
4…
8…
9…
9.2…
9.2.2.2…
9.2.2.3…
9.2.3…
9.2.3.12…
9.2.3.24
9.2.3.24.1…
9.2.3.24.10…
9.2.3.24.10.1.12…
9.2.3.24.10.2…
9.2.3.24.11…
9.2.3.25…
9.3…
10…
10.1.1…
10.1.3…
10.1.5…
10.1.7…
10.1.9…
10.1.11…
10.1.13…
10.1.15…
10.1.17…
10.2
10.2.1…
10.2.3…
10.2.5…
10.2.7…
10.3
11…
A…
C
C.1…
C.3…
C.5…
C.7…
C.9…
C.11…
C.13…
C.15…
D…
E…
F…
G…
G.2…
G.6
G.7
H…
I…
J…
K…
F Compression methods for EMS
F.1 LZSS compression
F.1.1 Introduction
F.1.2 LZSS Basic Algorithm
F.1.3 Informative Example.
...
...
F Compression methods for EMS |R5| p. 172
F.1 LZSS compression p. 172
F.1.1 Introduction p. 172
The LZSS compression algorithm is one of a number of compression algorithms generally referred to as "Dictionary Methods". These algorithms rely upon the fact that (in general) an input data buffer will contain repeating "patterns" or matching sequences of bytes.
The algorithms fall into 2 groups. Systems like LZ78 and LZW scan an input buffer and construct a "dictionary" of the most commonly occurring byte sequences or "phrases". This dictionary is pre-pended with the compressed data and the compressed data comprises an array of indices into the dictionary.
A second set is a modification of this in that the data dictionary is implicit in the uncompressed data buffer. All are based upon an algorithm developed and published in 1977 by Abraham Lempel and Jakob Ziv LZ77. A refinement of this algorithm, which is the basis for practically all the later methods in this group, is the LZSS algorithm developed in 1982 by Storer and Szymanski. These methods try to find if the character sequence currently being compressed has already occurred earlier in the input data and then, instead of repeating it, output only a pointer to the earlier occurrence. This is illustrated in the following diagram:
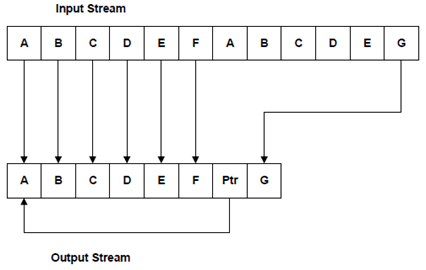
Figure F.1: Illustration of "Implicit Dictionary" compression methods
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
F.1.2 LZSS Basic Algorithm p. 172
The algorithm searches the window (a buffer moving back from the current position in the input data). It searches for the longest match with the beginning of the look-ahead buffer (a buffer moving forward from the current position in the input data) and outputs a pointer to that match. This pointer indicates a position and length of that data match. It is referred to here as a "Slice Descriptor".
Since it is possible that not even a one-character match can be found, the output cannot contain just pointers. Accordingly at times it is necessary to write literal octets into the output buffer. A block of literal octets is preceded by a "Literal Block Identifier" which indicates the length of the literal octet sequence that follows.
F.1.3 Informative Example. p. 173
The following is provided as an informative example using the input buffer shown below.

Step 1.
 Step 2.
Step 2.
 Step 3.
Step 3.
 Step 4.
Step 4.
 Step 5.
Step 5.

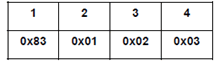
Starting position is byte 1 in the input buffer. For octets 1 to 3 there are no octet matches in the window for the look-ahead buffer. So write a literal octet sequence of 3 octets following a literal block header.
Current position is octet 4. Examining the look-ahead buffer and the window a 3 octet match is found beginning 3 octets before (octet 1) and of 3 octets in length. A 2 octet slice descriptor is added to the output buffer. The current position moves to octet 7 of the input buffer.
Figure F.4: Output buffer after the first slice descriptor is written
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
Current position is octet 7 in the input buffer (0x04). There are no matches in the window for this value so a 2 octet literal sequence is written to the end of the output buffer. The current position moves to octet 8 of the input buffer.
Current position is octet 8 of the input buffer. Comparing the window with the look-ahead buffer reveals a octet match from the current position with octets 1 to 6 of the input buffer. That is a 6 octet sequence beginning 7 octets back from the current position. A two-octet slice descriptor for this match is added to the output buffer. The current position moves to octet 14 of the input buffer (6 octets further on).
Figure F.6: Octet match slice descriptor is written into output buffer
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
Current position is octet 14 of the input buffer. Comparing the window with the look-ahead buffer reveals another 3 octet sequence match (0x01, 0x02, 0x03). This octet sequence occurs several times in the window within the 511 octets that the slice descriptor allows. Therefore several different (but valid) slice descriptors could be written (this would be implementation dependent). However in this example we will reference the initial 3 octets of the input buffer and write a slice descriptor indicating a 3 octet match beginning 13 octets behind the current position.
Figure F.7: Octet match slice descriptor is written into output buffer: the final output buffer
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
![]()
![]()
![]()